다중 평가 분석을 위한 진짜라벨과 혼동행렬 확장 모델
초록
본 논문은 여러 판정자들의 다중 평가 데이터를 분석하는 새로운 확률 모델 군을 제시한다. 기존의 Dawid‑Skene 모델을 일반화하여 “TrueLabel + Confusion” 패러다임 하에 계층적 베이지안 모델인 HybridConfusion을 도입하고, 합성 및 실제 데이터셋에서 기존 방법보다 일관되게 높은 진단 정확도와 해석 가능성을 보인다.
상세 분석
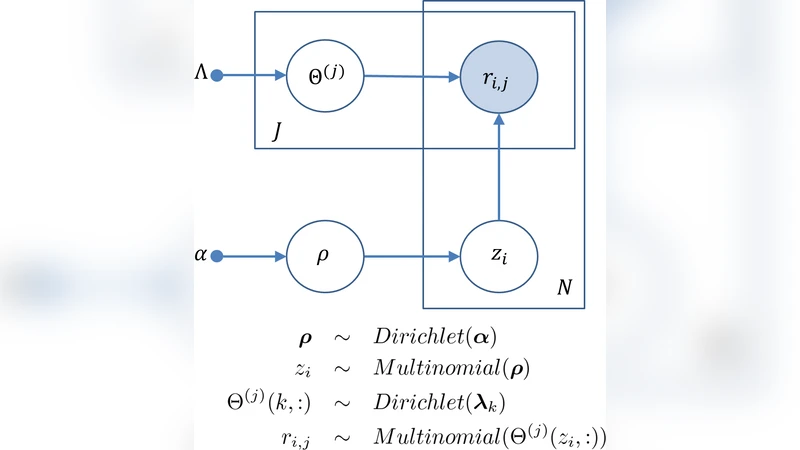
이 연구는 다중 라벨링 상황에서 판정자들의 오류 구조를 파악하고, 단순히 ‘정답’을 추정하는 것을 넘어 판정자 자체에 대한 진단 정보를 제공한다는 점에서 의미가 크다. 먼저 저자들은 전통적인 Dawid‑Skene(D‑S) 모델을 “TrueLabel + Confusion”이라는 두 단계 구조로 재해석한다. 여기서 TrueLabel은 실제 정답을 의미하고, Confusion은 각 판정자가 실제 라벨을 어떻게 오인하는지를 나타내는 전이 행렬이다. D‑S 모델은 각 판정자마다 고정된 혼동 행렬을 가정하지만, 실제 현장에서는 판정자의 전문성, 피로도, 업무 유형 등에 따라 혼동 행렬이 변동한다는 점을 간과한다.
이를 보완하기 위해 저자들은 세 가지 모델을 순차적으로 제안한다. 첫 번째는 “SharedConfusion”으로, 모든 판정자가 동일한 혼동 행렬을 공유한다는 가정 하에 베이지안 추정을 수행한다. 두 번째는 “IndividualConfusion”으로, 각 판정자마다 독립적인 혼동 행렬을 두어 보다 유연한 표현을 가능하게 한다. 하지만 개별 행렬을 모두 추정하면 파라미터 수가 급증해 과적합 위험이 커진다.
세 번째이자 핵심 모델인 “HybridConfusion”은 계층적 베이지안 구조를 도입한다. 개별 판정자의 혼동 행렬을 개별 파라미터로 두되, 이들 파라미터가 공통의 하이퍼파라미터(예: 디리클레 사전)로부터 공유된 사전 분포를 갖도록 설계한다. 이렇게 하면 데이터가 충분히 없을 때는 하이퍼파라미터가 판정자 간 정보를 ‘풀어주어’ 과적합을 방지하고, 충분한 데이터가 있을 때는 각 판정자의 특성을 충분히 반영한다. 또한 변분 추론(Variational Inference)과 Gibbs 샘플링을 병행해 효율적인 사후 추정 방법을 제공한다.
실험에서는 두 종류의 합성 데이터(혼동 행렬이 동일한 경우와 서로 다른 경우)와 실제 기업 내부에서 수집한 라벨링 데이터(다중 카테고리, 5명~20명 판정자)를 사용하였다. 결과는 HybridConfusion이 평균 정확도, 로그우도, 그리고 판정자별 혼동 행렬 추정 정확도에서 D‑S 및 다른 베이스라인을 모두 능가함을 보여준다. 특히 판정자 간 성능 차이가 큰 실제 데이터에서 HybridConfusion은 각 판정자의 강점과 약점을 시각화할 수 있는 ‘진단 대시보드’를 제공한다는 부가적인 장점을 갖는다.
이 논문의 주요 기여는 다음과 같다. (1) “TrueLabel + Confusion” 패러다임을 명확히 정의하고, 이를 기반으로 모델 스펙트럼을 체계화하였다. (2) 계층적 베이지안 설계를 통해 개별 판정자의 오류 특성을 공유 사전과 결합함으로써 데이터 효율성을 크게 향상시켰다. (3) 실용적인 진단 도구로서 판정자 교육·관리·품질 관리에 직접 활용 가능한 정량적 인사이트를 제공한다. 이러한 접근은 크라우드소싱뿐 아니라 기업 내부의 전문 판정자 집단에도 적용 가능하며, 향후 다중 라벨, 연속형 평점, 시간에 따른 판정자 변동 등을 포함한 확장 연구의 기반을 마련한다.
댓글 및 학술 토론
Loading comments...
의견 남기기