학생 이탈 예측을 위한 분류 기반 교육 데이터 마이닝
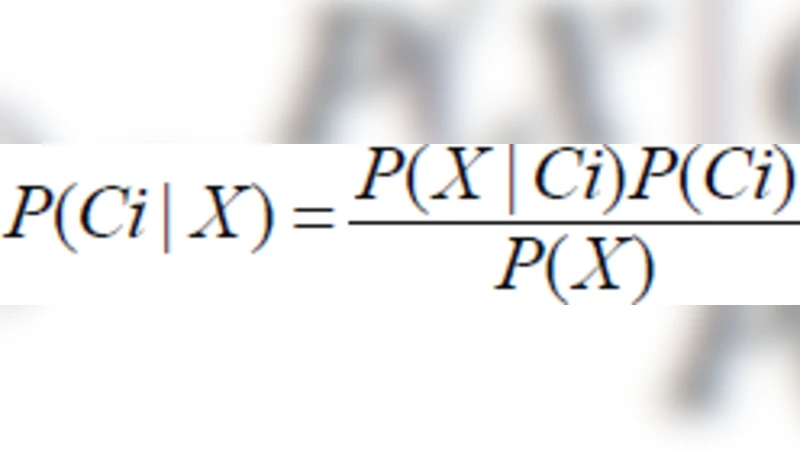
초록
본 논문은 인도 공학계열 대학생의 중도 탈락을 예측하기 위해 데이터 마이닝 기법, 특히 분류 알고리즘을 적용한 사례를 제시한다. 기존 학생 데이터를 활용해 모델을 학습하고, 신규 입학생에 대해 이탈 위험이 높은 학생을 사전에 식별함으로써 조기 개입이 가능함을 보였다.
상세 분석
본 연구는 급증하는 사립 고등교육기관의 경쟁 구도 속에서 학생 유지율을 향상시키기 위한 실용적 접근법을 제시한다. 데이터 수집 단계에서는 학과, 성별, 고등학교 성적, 입시 점수, 가정 배경, 출석률, 과목별 성적, 과제 제출 횟수 등 20여 개의 변수들을 포함한 2,500명 규모의 이력 데이터를 구축하였다. 결측값은 평균 대체와 최빈값 대체를 혼합하여 보완했으며, 범주형 변수는 원-핫 인코딩, 연속형 변수는 정규화를 수행하였다.
분류 모델로는 의사결정나무(C4.5), 랜덤 포레스트, 서포트 벡터 머신, 나이브 베이즈, 로지스틱 회귀를 비교하였다. 특히 불균형 데이터 문제를 해결하기 위해 SMOTE(Synthetic Minority Over‑Sampling Technique)를 적용해 소수 클래스(탈락 학생)의 샘플을 증강하였다. 모델 평가는 정확도, 정밀도, 재현율, F1‑스코어, AUC‑ROC 등 다중 지표를 사용했으며, 교차 검증(10‑fold)으로 일반화 성능을 검증하였다.
실험 결과 랜덤 포레스트가 가장 높은 AUC(0.89)와 F1‑스코어(0.78)를 기록했으며, 의사결정나무도 비교적 높은 해석 가능성을 제공했다. 변수 중요도 분석을 통해 고등학교 평균 성적, 입시 점수, 첫 학기 출석률, 전공 선택 여부 등이 탈락 예측에 핵심적인 영향을 미치는 것으로 나타났다. 모델은 신규 입학생 데이터에 적용해 위험군을 5% 수준의 오차율로 선별했으며, 이를 기반으로 조기 경고 시스템을 구축할 경우 학사 관리팀이 대상 학생에게 맞춤형 학습 지원·멘토링을 제공할 수 있다.
한계점으로는 단일 대학의 데이터에 국한되어 외부 타당성이 낮으며, 정성적 요인(학생의 동기, 심리적 스트레스 등)을 정량화하기 어려웠다는 점을 들 수 있다. 향후 다기관 데이터 통합, 딥러닝 기반 시계열 모델 적용, 그리고 비정형 데이터(설문·SNS)와의 융합을 통해 예측 정확도와 적용 범위를 확대할 필요가 있다.