자연어 새로운 단어 학습을 위한 퍼지 지식 표현 도구의 부드러운 적용
초록
본 논문은 퍼지 의미망에서 회원 함수(멤버십 함수)를 이용해 불확실하고 모호한 지식을 표현하고, 사용자가 제시한 새로운 단어를 학습하는 방법을 제시한다. 간단한 해석 정도 값으로 회원 함수를 초기화하고, 학습 과정에서 핵심 영역을 조정함으로써 사용자 객체와 시스템 객체 간의 대응을 정량화한다. 최종적으로 핵심 영역을 기반으로 한 결정 계수를 통해 최적 매칭을 선택한다.
상세 분석
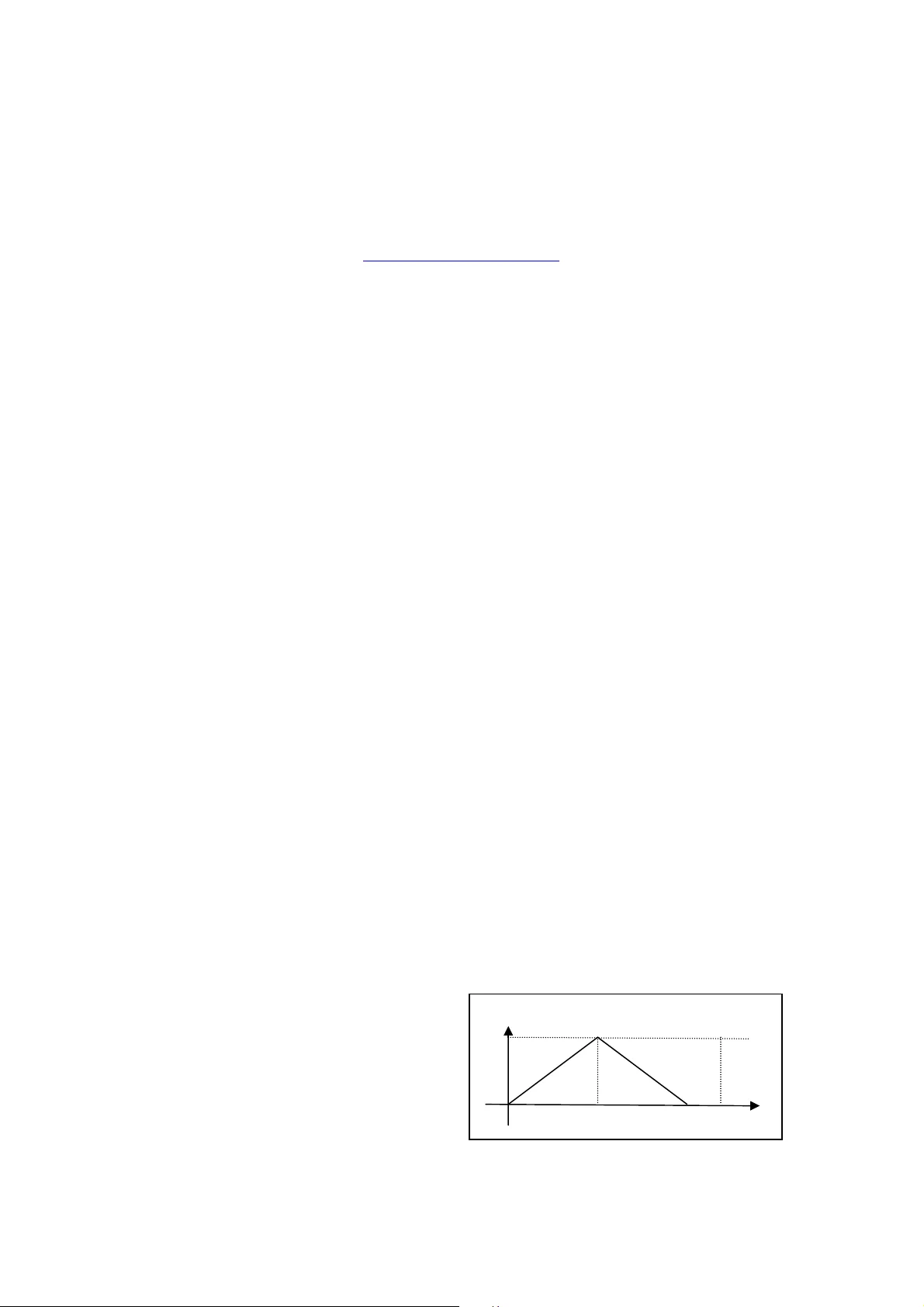
이 연구는 인간‑컴퓨터 상호작용에서 사용자가 시스템에 익숙하지 않은 용어를 사용할 때 발생하는 의미 불일치를 퍼지 논리를 통해 해결하고자 한다. 핵심 아이디어는 ‘해석 정도(value of interpretation)’라는 단일 수치를 입력받아 해당 값에 기반한 회원 함수를 자동으로 생성하는 것이다. 회원 함수는 전형적인 트라이앵글 혹은 가우시안 형태를 취할 수 있으며, 초기화 단계에서는 사용자가 제시한 해석 정도를 중심으로 좌·우측 퍼짐 정도를 대칭적으로 설정한다.
학습 단계에서는 사용자가 동일 객체에 대해 반복적으로 다른 해석 정도를 제공하면, 시스템은 기존 회원 함수의 핵심(코어)과 서포트(서포트 영역)를 재조정한다. 구체적으로, 새로운 값이 기존 코어보다 크면 코어의 오른쪽 경계를, 작으면 왼쪽 경계를 점진적으로 확대하거나 축소한다. 이러한 동적 조정 메커니즘은 사용자의 개인적 언어 습관을 반영하여 점진적으로 퍼지 의미망을 개인화한다는 점에서 의미가 크다.
또한, 객체(또는 목표) 간 매칭을 판단하기 위해 ‘결정 계수(decision coefficient)’를 도입한다. 결정 계수는 두 회원 함수의 코어가 겹치는 정도와 겹치는 구간의 넓이를 정량화한 값으로, 값이 클수록 두 객체가 의미적으로 유사하다고 판단한다. 이 방식은 전통적인 거리 기반 매칭(예: 유클리드 거리)보다 불확실성을 내포한 판단에 적합하며, 다중 목표 상황에서도 각 목표에 대한 가중치를 별도로 부여하지 않아도 된다.
기술적 강점으로는 (1) 단일 해석 정도 입력만으로 복잡한 퍼지 집합을 자동 생성한다는 단순성, (2) 학습 과정에서 실시간으로 함수 형태를 업데이트함으로써 사용자 맞춤형 의미 모델을 구축한다는 적응성, (3) 결정 계수를 통한 명확한 매칭 기준 제공을 들 수 있다. 반면 한계점은 초기 해석 정도가 지나치게 주관적일 경우 초기 회원 함수가 왜곡될 위험이 있으며, 다중 차원(예: 속성·관계) 퍼지 모델을 확장하기 위한 추가 연구가 필요하다는 점이다.