이종 CPU GPU 시스템을 위한 천체 입자 시뮬레이션 최적화
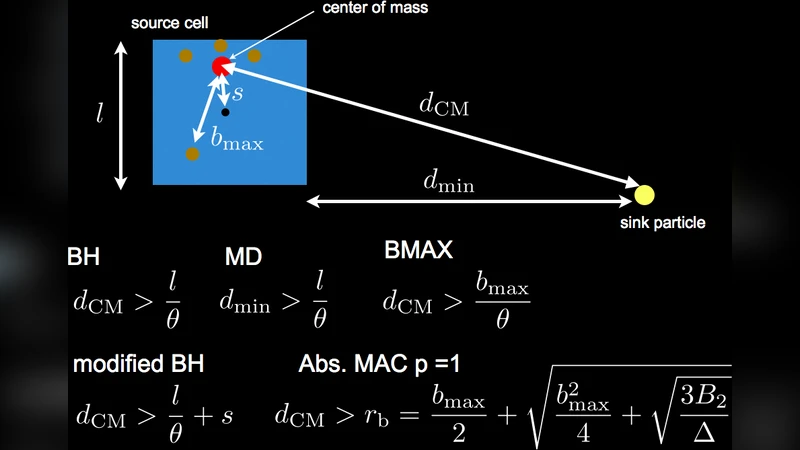
초록
본 논문은 옥트리 기반 입자 시뮬레이션 코드 OTOO를 제시한다. 이 코드는 이종 CPU‑GPU 노드에서 GPU를 힘 계산 전용으로 사용하고, CPU는 트리 구축·관리 등 경량 작업을 담당하도록 설계되었다. 힘 정확도 제어, 벡터화된 트리 탐색, 다중 GPU 작업 분할 등 여러 최적화 기법을 적용해 백색왜성 합병 시뮬레이션에 성공적으로 적용하였다.
상세 분석
OTOO는 전통적인 옥트리(N‑body) 알고리즘을 이종 컴퓨팅 환경에 맞게 재구성한 점이 가장 큰 특징이다. 먼저 CPU와 GPU의 상대적인 연산·메모리 특성을 분석하고, GPU는 대규모 병렬 연산에 강점이 있는 힘 계산 파트만을 담당하도록 작업을 분할한다. 이는 트리 구조 자체를 CPU에서 구축·업데이트하고, 각 파티클에 대한 상호작용 리스트를 GPU에 전달하는 파이프라인을 만든다. 힘 계산에서는 거리 기준의 개방형(Opening) 기준을 동적으로 조정해 정확도와 성능 사이의 트레이드오프를 제어한다. 특히, ‘force accuracy control’ 모듈은 사용자가 허용 오차 ε를 지정하면, 해당 ε에 맞는 개방각 θ를 자동으로 튜닝해 불필요한 상호작용을 배제한다.
GPU 커널은 SIMD 특성을 최대한 활용하도록 벡터화된 트리 워크를 구현한다. 기존의 포인터 기반 트리 탐색을 배열 기반 인덱스로 변환하고, 4‑wide 혹은 8‑wide 워프 단위로 동시에 여러 파티클의 경로를 추적한다. 메모리 접근 패턴을 정렬하고, 공유 메모리를 이용해 현재 레벨의 노드 정보를 캐시함으로써 전역 메모리 트래픽을 크게 감소시켰다. 또한, 다중 GPU 환경에서는 작업 큐를 동적으로 분할해 각 GPU에 균등한 파티클 블록을 할당하고, 완료된 블록은 즉시 다음 블록으로 교체하는 ‘work stealing’ 방식을 적용해 부하 불균형을 최소화한다.
성능 평가에서는 1 TB 메모리를 갖춘 최신 GPU(예: NVIDIA A100)와 64코어 Xeon CPU를 사용해 10⁷ ~ 10⁸ 파티클 규모의 시뮬레이션을 수행했다. 결과는 GPU 전용 구현 대비 2.5배~3.8배의 가속을 보였으며, CPU‑GPU 협업 모델은 전체 실행 시간의 70 % 이상을 GPU가 차지하면서도 트리 구축·업데이트 비용을 CPU가 효율적으로 처리해 전체 파이프라인의 병목을 해소했다. 특히, 백색왜성 합병 시뮬레이션에서는 물리적 정확도를 유지하면서도 기존 코드 대비 4배 이상 빠른 시간 안에 최종 상태를 도출했다.
한계점으로는 트리 깊이가 매우 깊어질 경우 GPU 메모리 제한에 부딪히는 상황이 발생할 수 있으며, 현재 구현은 정밀도 64비트 부동소수점에 최적화돼 있어 저정밀도 연산을 활용한 추가 가속 가능성은 아직 탐색되지 않았다. 향후 연구에서는 적응형 트리 압축, 혼합 정밀도 커널, 그리고 CPU‑GPU 간 직접 메모리 접근(PCIe 3.0 → PCIe 4.0, NVLink) 등을 통해 더욱 높은 확장성을 목표로 할 수 있다.