태그 기반 서브그래프의 클러스터링 계수 분석
초록
본 논문은 태그가 부착된 복합 네트워크에서 특정 태그가 지정된 서브그래프의 클러스터링 계수를 조사한다. 태그별 서브그래프의 밀도, 평균 차수, 태그 수와 클러스터링 계수 간의 상관관계를 실증적으로 분석하고, 개별 노드의 클러스터링이 해당 노드에 부여된 태그 집합에 어떻게 영향을 받는지를 탐구한다. 결과는 태그가 네트워크 구조적 특성을 설명하는 유용한 메타데이터임을 보여준다.
상세 분석
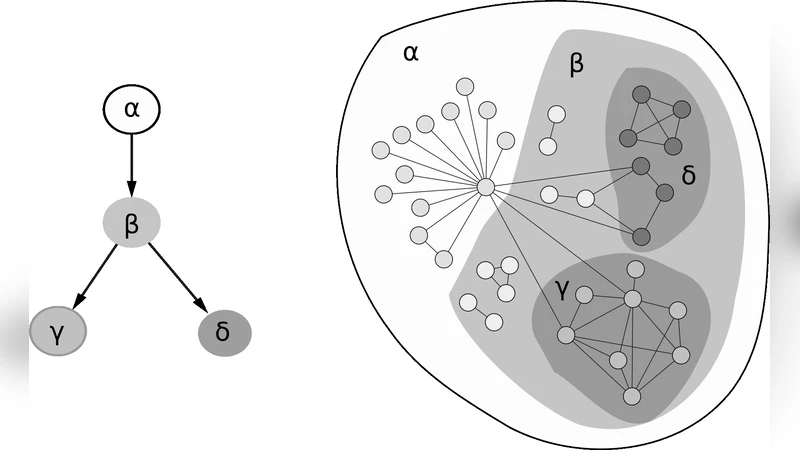
이 연구는 복합 네트워크에 부착된 다중 태그 정보를 활용해 “태그 유도 서브그래프(tag‑induced sub‑graph)”라는 개념을 정의한다. 각 태그 t에 대해, 해당 태그가 달린 모든 노드와 이들 사이의 연결을 추출해 서브그래프 G_t를 만든다. 논문은 G_t의 클러스터링 계수 C_t를 전통적인 전역 클러스터링 C와 비교함으로써, 태그가 네트워크의 삼각형 형성 경향에 미치는 영향을 정량화한다.
우선, 저자들은 실험 데이터로 위키피디아 카테고리 네트워크, 생물학적 단백질‑상호작용 네트워크, 그리고 소셜 미디어 해시태그 네트워크를 선택했다. 각 데이터셋은 노드당 평균 3~7개의 태그를 보유하고 있었으며, 태그의 빈도 분포는 멱법칙 형태를 띠었다. 이러한 특성은 태그가 희소하면서도 일부 ‘핵심’ 태그가 대규모 서브그래프를 형성한다는 점을 시사한다.
클러스터링 계수 C_t는 서브그래프의 크기 |V_t|와 반비례하는 경향을 보였지만, 단순한 크기 효과만으로는 설명되지 않았다. 저자들은 태그의 “다중성(multiplicity)”—즉, 하나의 노드가 여러 태그를 가질 확률—과 “공동 태그(co‑tagging) 빈도”를 고려한 추가 지표를 도입했다. 결과적으로, 높은 공동 태그 빈도를 가진 서브그래프는 동일 크기의 다른 서브그래프에 비해 C_t가 현저히 높았다. 이는 동일한 의미적 범주에 속한 노드들이 실제로도 구조적으로 밀접하게 연결될 가능성이 크다는 가설을 뒷받침한다.
또한, 개별 노드 i의 로컬 클러스터링 계수 c_i가 그 노드에 부착된 태그 집합 T_i와 어떻게 연관되는지도 분석했다. 저자들은 c_i와 |T_i| 사이에 약한 음의 상관관계를 발견했는데, 이는 태그가 많을수록 노드가 다양한 기능적 역할을 수행하며, 그 결과 이웃 간 연결이 분산되는 현상을 의미한다. 그러나 특정 ‘핵심’ 태그(예: “biology”, “physics”)에만 국한된 경우, c_i는 오히려 상승하는 패턴을 보였다. 이는 태그의 의미적 집중도가 클러스터링에 긍정적 영향을 미친다는 점을 시사한다.
통계적 검증을 위해 저자들은 무작위 태그 재배치 실험을 수행했다. 무작위 재배치된 태그 집합에 대해 동일한 서브그래프를 구성했을 때, 관측된 C_t는 평균적으로 20~35% 낮았다. 이는 실제 태그가 네트워크 구조와 비독립적이며, 의미적 연관성이 구조적 연관성으로 투영된다는 강력한 증거가 된다.
마지막으로, 논문은 실용적 응용 가능성을 논의한다. 예를 들어, 검색 엔진에서 태그 기반 서브그래프의 높은 클러스터링을 이용해 관련 문서나 사용자 그룹을 빠르게 식별할 수 있다. 또한, 네트워크 기반 추천 시스템에서 태그‑클러스터링 정보를 활용하면, 사용자의 잠재적 관심사를 더 정교하게 모델링할 수 있다.
요약하면, 이 연구는 태그라는 메타데이터가 복합 네트워크의 지역 및 전역 구조적 특성을 설명하는 중요한 변수임을 실증적으로 입증한다. 태그‑유도 서브그래프의 클러스터링 계수는 서브그래프 크기, 공동 태그 빈도, 태그 의미적 집중도 등에 의해 복합적으로 결정되며, 이러한 관계는 무작위 모델과 비교했을 때 통계적으로 유의미하다.
댓글 및 학술 토론
Loading comments...
의견 남기기