긍정 단어는 부정 단어보다 정보량이 적다
초록
이 논문은 영어·독일어·스페인어의 감정 어휘 사전을 활용해 웹 전체에서 단어 사용 빈도를 분석하고, 긍정적 의미를 가진 단어가 부정적 의미를 가진 단어보다 더 자주 등장한다는 사실을 확인한다. 또한 자기정보량(‑log P)과 감정 가치(밸런스) 사이에 부의 상관관계가 존재함을 보여, 부정 단어가 더 높은 정보량을 전달한다는 결론을 도출한다.
상세 분석
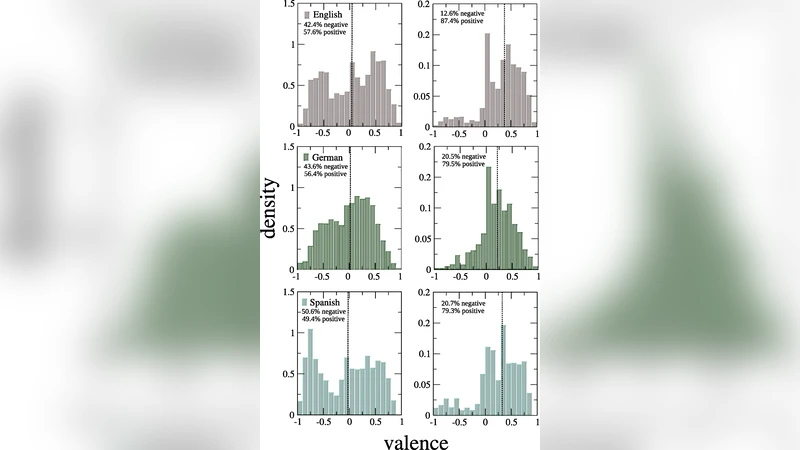
본 연구는 세 가지 공인된 감정 어휘 사전(영어 1034 단어, 독일어 2902 단어, 스페인어 1034 단어)을 기반으로 각 단어의 밸런스(valence) 점수를 확보하고, 구글 N‑gram(10¹² 토큰) 데이터베이스에서 추출한 실제 사용 빈도와 결합하였다. 먼저 사전 내 평균 밸런스가 0에 가깝게 중립적임을 확인했으며, 이는 사전 자체가 감정 편향을 내포하지 않음을 의미한다. 이후 빈도 가중 평균을 적용해 사용 빈도에 따라 가중된 밸런스 분포를 계산했을 때, 세 언어 모두 평균 밸런스가 약 0.2~0.3 정도로 양의 방향으로 크게 이동함을 발견했다. 이는 인터넷 상에서 긍정적 단어가 부정적 단어보다 현저히 더 많이 사용된다는 실증적 증거이다. 통계적 검증으로는 Wilcoxon 부호 검정을 사용했으며, 95 % 신뢰구간에서 평균 차이가 모두 0보다 크게 나타났다(영어 0.257 ± 0.032, 독일어 0.167 ± 0.017, 스페인어 0.287 ± 0.035).
정보량 측정은 자기정보량 I(w)=−log P(w)와 N‑gram 확장 정보량(I₂, I₃, I₄)을 활용하였다. 자기정보량은 빈도와 비선형적으로 연결되므로, 밸런스와 직접 비교했을 때 더 높은 상관계수를 보였다. Pearson 상관계수 ρ(v, I)는 영어 −0.368, 독일어 −0.325, 스페인어 −0.402로 모두 통계적으로 유의(p < 0.001)했으며, 이는 밸런스가 낮을수록(즉, 부정적일수록) 자기정보량이 높아진다는 명확한 부의 관계를 시사한다. N‑gram 기반 정보량에서도 유사한 부의 상관관계가 유지되었으며, 전통적인 서적 코퍼스(책)에서 추출한 빈도와 비교했을 때도 결과가 일관되었다.
연구는 기존 Zipf의 법칙과 Piantadosi의 정보‑길이 관계를 확장하여 감정적 의미가 언어 사용에 미치는 영향을 정량화하였다. 긍정 단어가 더 자주 사용되는 현상은 Pollyanna 가설을 지지하며, 부정 단어가 상대적으로 희귀하지만 높은 정보량을 전달한다는 점은 커뮤니케이션 효율성 관점에서 흥미로운 함의를 제공한다. 다만, 사전이 단어 수준에 국한되고 구문·다중어 의미를 반영하지 못한다는 제한점이 있다. 또한 구글 N‑gram이 웹 기반 텍스트에 편중되어 있어, 구어·비공식 텍스트와의 차이를 완전히 배제하기는 어렵다. 향후 연구에서는 감정 어휘의 다중 차원(예: 각성도)과 문맥 의존성을 고려한 심층 신경망 모델을 적용해 정보량‑감정 관계를 보다 정교하게 탐구할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기