역사 데이터와 과정 지식의 예측 비교
초록
본 논문은 동적 시스템 예측 시, 부분적으로만 알려진 과정 지식과 과거 관측 데이터 중 어느 쪽이 더 효과적인지를 실험적으로 검증한다. 특히 혼돈적 특성을 가진 시스템에서 과정 지식이 구조적 오류나 파라미터 오차를 포함할 경우, 순수 데이터 기반 모델이 더 정확한 예측을 제공한다는 결과를 제시한다.
상세 분석
이 연구는 예측 문제를 두 가지 접근법, 즉 (1) 과정 지식 기반 모델(physics‑based model)과 (2) 데이터 기반 모델(통계·머신러닝)으로 구분하고, 각각이 갖는 불확실성 유형을 체계적으로 분류한다. 과정 지식의 오차는 크게 구조적 미스스펙(모델 구조 자체가 실제 시스템을 제대로 반영하지 못함), 파라미터 미스스펙(정확한 매개변수값을 모름), 그리고 외부 교란에 대한 부적절한 처리로 나뉜다. 반면 데이터 기반 접근은 관측 노이즈와 샘플 부족이라는 제한을 가진다.
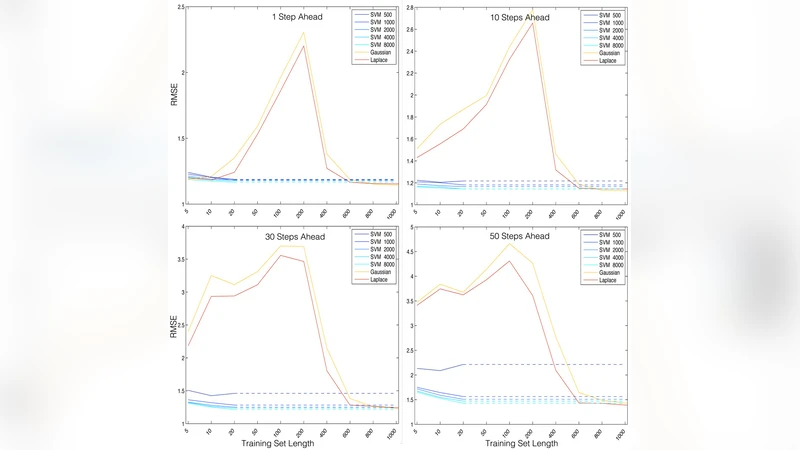
시뮬레이션은 로지스틱 맵, 로렌츠 시스템, 그리고 고차원 혼돈 회귀 모델 등 세 가지 대표적인 비선형·혼돈 시스템을 대상으로 수행되었다. 과정 지식 모델은 실제 시스템 방정식을 그대로 사용하거나, 의도적으로 구조를 단순화하거나 파라미터를 왜곡시켜 미스스펙 상황을 만든다. 데이터 기반 모델은 ARIMA, 딥러닝 기반 LSTM, 그리고 커널 회귀(KRR)를 적용했으며, 훈련 데이터 길이와 노이즈 수준을 다양하게 조절하였다.
성능 평가는 평균 제곱 오차(MSE)와 예측 가능 시간(prediction horizon) 두 지표를 사용하였다. 결과는 다음과 같다. (1) 정상적인 과정 지식이 제공될 경우, 데이터 기반보다 월등히 긴 예측 가능 시간을 확보한다. (2) 구조적 미스스펙이 존재하면, 특히 비선형 항을 누락하거나 차원을 축소한 경우, 데이터 기반 모델이 동일한 MSE 수준에서 더 긴 예측 가능 시간을 보여준다. (3) 파라미터 오차가 10 % 이하일 때는 과정 지식이 여전히 우세하지만, 오차가 20 %를 초과하면 데이터 기반 모델이 역전한다. (4) 관측 노이즈가 큰 경우에도 데이터 기반 모델은 정규화와 잡음 억제 기법을 통해 비교적 견고한 성능을 유지한다.
이러한 결과는 “완전한 과정 지식이 존재한다면 데이터는 필요 없다”는 직관에 반하는 중요한 시사점을 제공한다. 특히 실무에서 모델 구조 자체가 복잡하거나, 파라미터 추정이 어려운 경우, 충분히 긴 과거 기록이 확보돼 있다면 데이터 기반 접근이 더 실용적일 수 있다. 또한, 혼돈 시스템에서는 작은 구조적 오류가 예측 오류를 기하급수적으로 확대시키는 특성 때문에, 데이터 기반 모델이 상대적으로 안정적인 예측을 제공한다는 점이 강조된다.
댓글 및 학술 토론
Loading comments...
의견 남기기