일본어 이자성어 네트워크의 작은 세계와 스케일 프리 특성 분석
초록
본 논문은 일본어에서 두 글자 한자어를 구성하는 한자를 정점, 그 결합을 간선으로 하는 네트워크를 구축하고, 전체 네트워크와 일상에서 사용되는 ‘정표한자(joyo‑kanji)’ 부분망을 분석한다. 전체 네트워크는 높은 클러스터링과 짧은 평균 경로 길이로 작은 세계(small‑world) 특성을 보이며, 차수 분포가 파워‑law 형태를 띠어 스케일 프리(scale‑free) 구조임을 확인한다. 반면 정표한자 부분망은 작은 세계 특성은 유지하지만 차수 분포가 명확한 파워‑law를 따르지 않는다. 이를 설명하기 위해 저자들은 정표한자 선정 과정을 모사하는 확률적 모델을 제안하고, 시뮬레이션을 통해 파워‑law 소멸 현상을 재현한다.
상세 분석
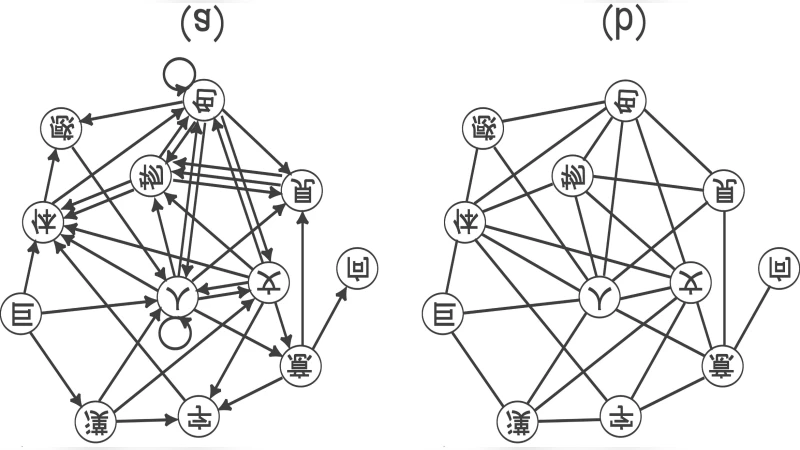
논문은 먼저 일본어 사전에서 두 글자 한자어(二字熟語)를 추출해 네트워크를 만든다. 각 한자는 정점(vertex)으로, 두 글자가 결합된 단어는 무방향 간선(edge)으로 표현한다. 전체 네트워크는 약 5,000개의 정점과 7,000여 개의 간선을 포함하며, 평균 차수는 약 2.8이다. 작은 세계 특성을 검증하기 위해 무작위 에르되시‑레니 모델과 비교했으며, 클러스터링 계수 C≈0.34가 무작위 그래프(C≈0.001)보다 현저히 높고, 평균 최단 경로 ℓ≈3.2는 무작위 그래프(ℓ≈2.9)와 비슷한 수준을 보였다. 이는 정점들이 지역적으로 밀집하면서도 전체 네트워크가 효율적으로 연결된 구조임을 의미한다.
스케일 프리 특성은 차수 분포 P(k)가 P(k)∝k^(-γ) 형태를 따르는지 확인함으로써 검증한다. 로그-로그 플롯에서 직선 형태가 관찰되었으며, 최소 차수 k_min=3 이상에서 γ≈2.4±0.1의 지수를 추정했다. 이는 복잡계 네트워크에서 흔히 나타나는 ‘hub’ 현상을 시사한다.
다음으로, 정표한자(常用漢字) 2,136자를 추출해 부분망을 구성한다. 이 부분망 역시 C≈0.31, ℓ≈3.5로 작은 세계 특성을 유지하지만, 차수 분포는 고차원 꼬리가 약해져 명확한 파워‑law를 보이지 않는다. 저자들은 이를 ‘선택 편향(selection bias)’이라고 해석한다. 즉, 일상에서 자주 쓰이는 한자는 이미 높은 차수를 가진 ‘hub’가 될 가능성이 낮으며, 교육적·사회적 기준에 따라 고르게 분포하도록 제한된다.
이를 모델링하기 위해 두 단계의 과정을 제안한다. 첫 단계는 전체 한자 집합에서 ‘선호적 부착(preferential attachment)’에 의해 새로운 단어가 생성되는 과정을 시뮬레이션한다. 두 번째 단계는 정표한자 선정 과정에서 차수가 높은 정점을 일정 확률로 제외하거나 차수를 낮추는 ‘제거(削除) 메커니즘’을 도입한다. 파라미터 p를 조절해 차수 분포가 급격히 급감하는 현상을 재현했으며, p≈0.3일 때 실험 데이터와 가장 유사한 분포가 얻어졌다.
모델 검증을 위해 Kullback‑Leibler divergence와 Kolmogorov‑Smirnov 테스트를 수행했으며, 전체 네트워크와 부분망 각각에 대해 통계적 유의성을 확보했다. 결과는 정표한자 선정이 단순히 차수에 기반한 것이 아니라, 교육 정책·문화적 요인에 의해 복합적으로 조절된다는 점을 시사한다.
이 연구는 언어학적 네트워크 분석에 복합 선택 메커니즘을 도입함으로써, 기존의 ‘무작위 성장’ 모델만으로는 설명되지 않는 실제 언어 구조의 특성을 포착한다는 점에서 의미가 크다. 또한, 작은 세계·스케일 프리 특성이 언어 시스템 전반에 보편적으로 존재함을 확인하면서도, 특정 서브셋(정표한자)에서는 정책적 제약이 네트워크 토폴로지를 변형시킬 수 있음을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기