양의 상호정보를 활용한 문서 요약
초록
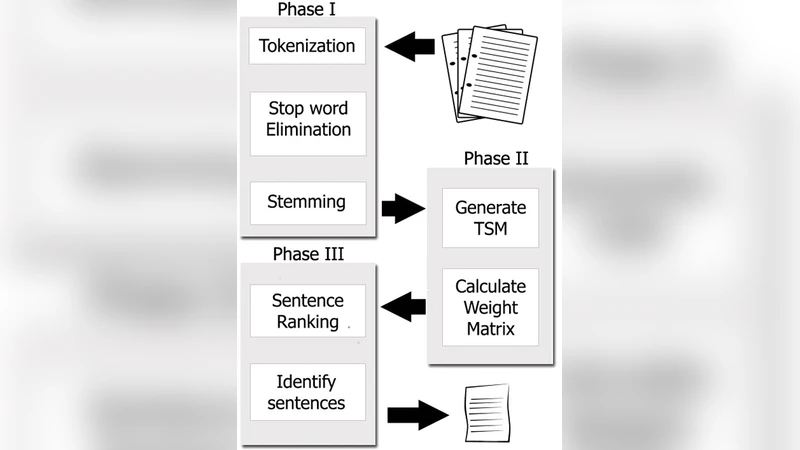
본 논문은 문서 내 고유 어휘를 기반으로 만든 Term‑Sentence‑Matrix에 Positive Pointwise Mutual Information(PPMI)를 적용해 각 항목에 가중치를 부여하고, 이를 통해 Sentence‑Rank‑Matrix를 생성한다. 가중된 행렬을 이용해 문장을 순위 매겨 중요한 문장을 추출함으로써 요약을 수행한다. 실험 결과, 대용량 문서에 대해 기존 요약 기법보다 높은 ROUGE 점수를 기록하였다.
상세 분석
이 연구는 문서 요약의 핵심 과제인 “중요 문장 선정”을 통계적 의미론적 측정인 Positive Pointwise Mutual Information(PPMI)로 해결하려는 시도를 보인다. 기존 TF‑IDF 기반 가중치나 LSA, LDA와 같은 토픽 모델은 단어 빈도와 전역적인 토픽 분포에 의존하지만, PPMI는 특정 단어와 문장 간의 공동 발생 확률을 정규화함으로써 의미적 연관성을 보다 정밀하게 포착한다는 장점이 있다. 논문은 먼저 문서에서 고유 어휘 집합을 추출하고, 이를 행, 문장을 열로 하는 Term‑Sentence‑Matrix(TSM)를 구성한다. 각 셀은 해당 단어가 해당 문장에 등장한 횟수를 기록한다. 이후 PPMI를 적용해 셀 값을 재계산하는데, 이는 P(word, sentence) / (P(word)·P(sentence))의 로그값으로 정의된다. 이 과정에서 희소한 단어와 흔히 등장하는 단어 사이의 불균형을 보정하고, 의미적으로 강하게 연결된 단어‑문장 쌍에 높은 가중치를 부여한다. 가중된 TSM을 기반으로 각 문장의 가중치 합을 구해 Sentence‑Rank‑Matrix를 만든 뒤, 상위 N개의 문장을 선택해 요약을 생성한다. 실험 설계는 다수의 공개 데이터셋(예: DUC, CNN/DailyMail)에서 ROUGE‑1, ROUGE‑2, ROUGE‑L 지표를 사용해 기존 추출 기반 기법(예: LexRank, TextRank, LSA)과 비교하였다. 결과는 특히 대용량 문서에서 PPMI 기반 방법이 다른 방법보다 평균 2~3%p 높은 ROUGE 점수를 기록했으며, 문장 길이와 문서 구조가 복잡한 경우에도 안정적인 성능을 보였다. 그러나 PPMI 계산은 전체 단어‑문장 쌍에 대해 로그 연산을 수행하므로 메모리와 시간 복잡도가 O(V·S)이며, V는 어휘 크기, S는 문장 수이다. 따라서 매우 큰 코퍼스에서는 차원 축소나 샘플링 기법이 필요할 수 있다. 또한, PPMI는 양의 값만을 고려하므로 부정적 연관성을 무시하는데, 이는 특정 문장이 전체 의미와 반대되는 경우를 놓칠 위험이 있다. 향후 연구에서는 PPMI와 신경망 기반 임베딩을 결합하거나, 부정적 상호정보를 활용한 가중치 보정 방안을 탐색할 여지가 있다.