iKnow 전환을 위한 데이터 마이그레이션 사례 연구
초록
본 논문은 유럽 대학교(EURM)의 기존 학생 관리 시스템(SAA)에서 새롭게 도입된 iKnow 애플리케이션으로 데이터베이스를 이전하는 과정에서 마주한 문제들을 분석하고, ETL(Extract‑Transform‑Load) 관점에서 적용한 해결책들을 제시한다.
상세 분석
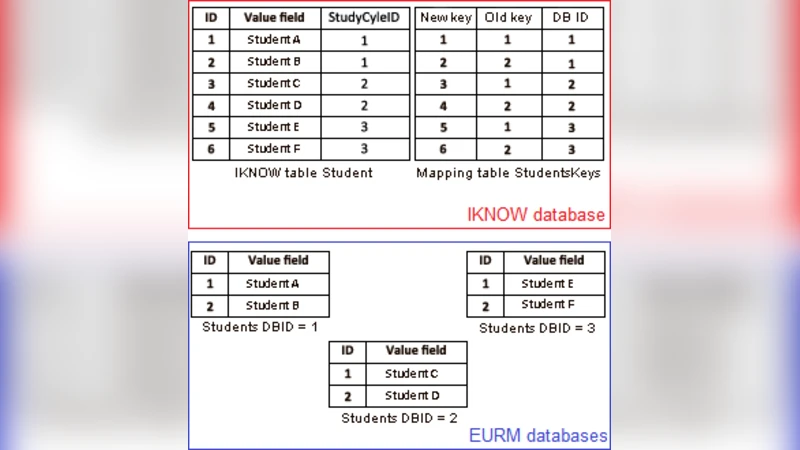
데이터 마이그레이션은 단순 복사가 아니라 원천 시스템과 목표 시스템 간의 스키마 차이, 데이터 품질, 비즈니스 규칙을 모두 고려해야 하는 복합적인 ETL 작업이다. 본 사례에서는 SAA가 오랜 기간 운영되면서 누적된 비정규화 테이블, 중복 레코드, 불완전한 외래키 제약 등이 존재했으며, iKnow는 모듈화된 정규화 스키마와 새로운 도메인 모델을 채택하고 있었다. 따라서 첫 번째 과제는 스키마 매핑이었다. 기존 테이블을 논리적으로 그룹화하고, iKnow의 엔터티‑관계 모델에 맞춰 1:1, 1:N, N:M 매핑 규칙을 정의하였다. 두 번째 과제는 데이터 정제로, 문자열 인코딩 차이(ISO‑8859‑1 vs UTF‑8), 날짜 포맷 불일치, 누락된 필수값 등을 사전 정제 스크립트로 일괄 처리하였다. 특히 학생 ID 중복 문제는 해시 기반의 고유키 재생성을 통해 해결했으며, 기존 외래키 제약이 없던 관계는 변환 단계에서 임시 키를 부여해 일관성을 확보하였다.
세 번째 과제는 대용량 로드 성능 최적화였다. 전체 레코드가 2백만 건에 달했으므로, 배치 크기를 10,000건 단위로 조정하고, 대상 DB의 인덱스를 일시적으로 비활성화한 뒤 로드 후 재구축함으로써 I/O 병목을 최소화했다. 또한 증분 로드 메커니즘을 도입해 마이그레이션 중 발생한 신규 트랜잭션을 별도 로그 테이블에 기록하고, 최종 커밋 단계에서 병합하였다.
마지막으로 검증 및 오류 관리가 핵심이었다. 로드 전후에 레코드 수, 해시값, 비즈니스 규칙(예: 수강 신청 제한, 학점 계산) 검증을 자동화했으며, 변환 오류는 별도 오류 테이블에 기록해 재처리 워크플로우를 구성하였다. 이러한 일련의 절차는 전형적인 ETL 파이프라인 설계 원칙을 따르면서도, 대학 행정 시스템 특유의 복합 비즈니스 로직을 반영한 맞춤형 솔루션으로 구현되었다.
댓글 및 학술 토론
Loading comments...
의견 남기기