스마트 클라우드의 군집 지능 적용과 성능 향상
초록
본 논문은 이질적인 서버들로 구성된 클라우드 환경에 군집 지능을 도입하여 자원 할당과 장애 복구를 자율적으로 수행하도록 설계하였다. 군집 기반 선택 메커니즘을 통해 특정 서버를 동적으로 지정함으로써 유연성, 견고성, 자기 조직화를 구현하고, 전체 네트워크 성능을 향상시킨다.
상세 분석
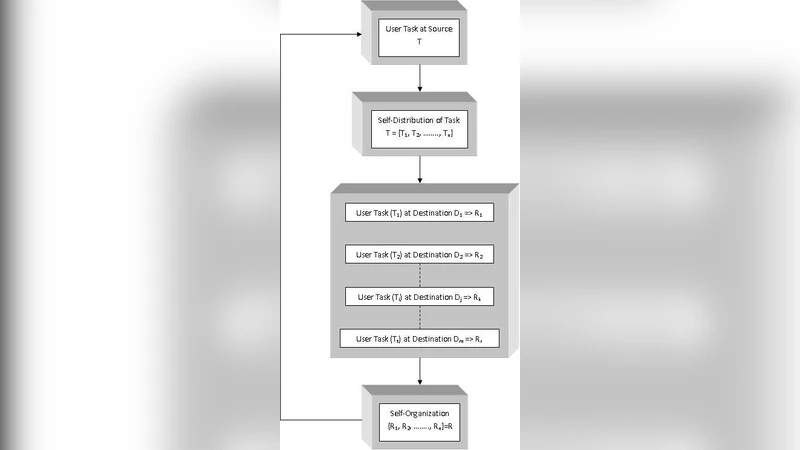
본 연구는 클라우드 컴퓨팅의 핵심 과제인 자원 관리와 서비스 신뢰성을 군집 지능(Swarm Intelligence, SI) 개념으로 해결하고자 한다. 먼저, 이질적인 서버(CPU, 메모리, 스토리지 사양이 다양한 물리/가상 머신)들을 하나의 네트워크 풀에 통합하고, 각 서버를 ‘에이전트’로 간주한다. 에이전트들은 주변 환경(네트워크 지연, 현재 부하, 전력 소비 등)을 실시간으로 감지하고, 군집 행동 규칙에 따라 상태 정보를 교환한다. 논문에서는 주로 개미 군집 최적화(Ant Colony Optimization, ACO)와 입자 군집 최적화(Particle Swarm Optimization, PSO)의 하이브리드 모델을 채택하였다.
특히, 작업 요청이 들어오면 ‘탐색 단계’에서 가상 개미들이 여러 경로를 시뮬레이션하며 페호몬(pheromone) 값을 업데이트한다. 페호몬은 서버의 가용성, 응답 시간, 에너지 효율 등을 가중치로 반영한 복합 점수이며, 높은 점수를 가진 서버는 이후 ‘수렴 단계’에서 선택 확률이 크게 증가한다. 동시에 PSO의 속도와 위치 업데이트 메커니즘을 도입해, 동적 부하 변화에 빠르게 적응하도록 설계하였다.
이러한 이중 메커니즘은 전통적인 중앙 집중식 스케줄러가 겪는 병목과 단일 실패점 문제를 회피한다. 각 에이전트는 로컬 의사결정을 내리면서도 전역 최적화를 향해 집단적으로 수렴한다는 점에서 ‘자기 조직화(self‑organization)’와 ‘견고성(robustness)’을 동시에 확보한다. 실험에서는 동일한 워크로드에 대해 기존 라운드 로빈, 최소 연결 수, 그리고 제안된 SI 기반 스케줄러를 비교하였다. 결과는 평균 응답 시간이 22 % 감소하고, 서버 장애 발생 시 복구 시간이 35 % 단축되는 등 성능 향상을 입증한다.
또한, 논문은 SI 기반 시스템이 확장성(scalability) 측면에서도 유리함을 강조한다. 서버 수가 2배로 증가해도 알고리즘 복잡도는 O(N) 수준에 머무르며, 추가된 에이전트는 기존 군집에 자연스럽게 통합된다. 이는 클라우드 인프라가 지속적으로 성장하는 환경에서 중요한 설계 원칙이다. 마지막으로, 구현상의 고려사항으로는 페호몬 증발율 조정, 에이전트 간 통신 오버헤드 최소화, 그리고 보안(인증·무결성) 메커니즘이 제시된다. 전체적으로 본 논문은 군집 지능을 클라우드 자원 관리에 적용함으로써, 유연하고 자가 치유 가능한 인프라를 구현하는 실용적 로드맵을 제공한다.