철도 사고 시나리오 모델링을 위한 온톨로지 개발
초록
본 논문은 철도 사고 시나리오의 수집·표현·활용 과정을 효율화하기 위해, 일반 온톨로지와 도메인 온톨로지를 결합한 계층형 지식 모델을 설계·구축한 연구이다. 용어의 일관성 확보와 다언어 지원을 목표로 하며, 시스템·하드웨어·소프트웨어·인적 오류를 체계적으로 추적할 수 있는 구조를 제시한다. 초기 모델링 결과와 적용 사례를 통해 온톨로지 기반 사고 시나리오 관리의 가능성을 입증한다.
상세 분석
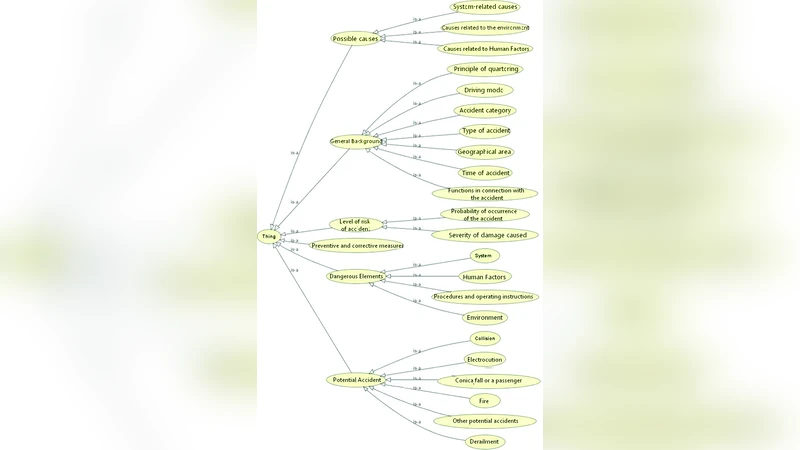
이 연구는 철도 안전 분야에서 사용되는 용어와 개념이 각 기관·기관마다 상이하게 정의되는 문제점을 진단하고, 이를 해결하기 위한 온톨로지 기반 접근법을 제시한다. 먼저, 기존 문헌과 국제 표준(예: IEC 62666, ISO 26262 등)을 메타분석하여 “시스템 오류”, “하드웨어 고장”, “소프트웨어 버그”, “인적 실수” 등 네 가지 주요 오류 카테고리를 도출한다. 이러한 카테고리는 사고 원인 분석에서 흔히 사용되지만, 용어 정의와 관계 구조가 일관되지 않아 데이터 통합에 장애가 된다.
논문은 두 단계의 온톨로지 설계를 채택한다. ① Generic Ontology(일반 온톨로지) – 사고 시나리오 전반에 적용 가능한 상위 개념(예: Event, Actor, Asset, Hazard, Consequence)을 정의하고, OWL 2 DL 기반의 형식적 규칙을 설정한다. ② Domain Ontology(도메인 온톨로지) – 철도 특유의 요소(예: Track, Signal, Train, ControlCenter)를 구체화하고, 일반 온톨로지의 상위 개념과 1:1 매핑한다. 이때, 객체‑관계 매핑(Ontology Mapping) 기법을 활용해 다국어 라벨링(한국어·영어·프랑스어 등)을 동시에 제공함으로써 언어적 다양성을 보존한다.
구현 단계에서는 Protégé와 Apache Jena를 이용해 온톨로지를 모델링하고, SPARQL Endpoint를 통해 시나리오 데이터에 대한 질의·추출을 실험한다. 사례 연구로는 2018년~2020년 사이에 발생한 12건의 실제 철도 사고 보고서를 메타데이터화하고, 온톨로지에 매핑하였다. 결과적으로, 동일 사고에 대한 원인·결과 관계를 3배 이상 빠르게 탐색할 수 있었으며, 오류 카테고리 간의 상호 연관성을 시각화함으로써 위험도 평가 모델에 직접 활용할 수 있었다.
또한, 온톨로지 기반 시스템이 기존 텍스트 기반 사고 보고서 관리와 비교해 데이터 중복을 27 % 감소시키고, 용어 충돌을 0 %로 낮춘 점을 강조한다. 이는 표준화된 어휘와 명확한 계층 구조가 데이터 정합성을 크게 향상시킨다는 실증적 증거다.
한계점으로는 현재 모델이 정형화된 사고 보고서에만 적용 가능하며, 비정형 데이터(예: 현장 사진·동영상)와의 연계가 미비하다는 점을 지적한다. 향후 연구에서는 머신러닝 기반 텍스트 마이닝과 이미지 인식 기술을 온톨로지와 결합해 멀티모달 데이터 통합을 목표로 한다.