데이터 샘플링 간격이 컴퓨터 기반 K지수에 미치는 영향
초록
본 연구는 1초와 1분 간격으로 기록된 지자기 데이터가 컴퓨터 알고리즘을 통해 산출된 K지수에 어떤 차이를 일으키는지 평가한다. IAGA가 승인한 FMI 알고리즘을 적용해 2009년 1월 1일부터 2010년 5월 31일까지 포트오프프랑세 관측소 데이터를 분석했으며, 저활동 및 중간활동 구간에서 3시간 변동값과 K지수의 변동 양상을 비교하였다. 결과는 샘플링 간격이 짧을수록 급격한 변동을 더 정확히 포착해 K지수가 상승하는 경향을 보였으며, 특히 활동이 높은 시기에 차이가 크게 나타났다.
상세 분석
이 논문은 전통적인 K지수 산출 방식이 인간 관측자에 의존했으나, 디지털 관측소와 INTERMAGNET 네트워크의 확산으로 자동화된 알고리즘이 필수적인 상황에 놓였음을 강조한다. 1991년 비엔나 회의에서 IAGA가 채택한 네 가지 알고리즘 중 하나인 FMI(Frederiksberg Magnetic Institute) 알고리즘을 선택해 실험에 적용했으며, 이는 3시간 구간 내 최대 변동(range)을 측정해 사전 정의된 클래스(0~9)와 매핑하는 전형적인 절차를 따른다.
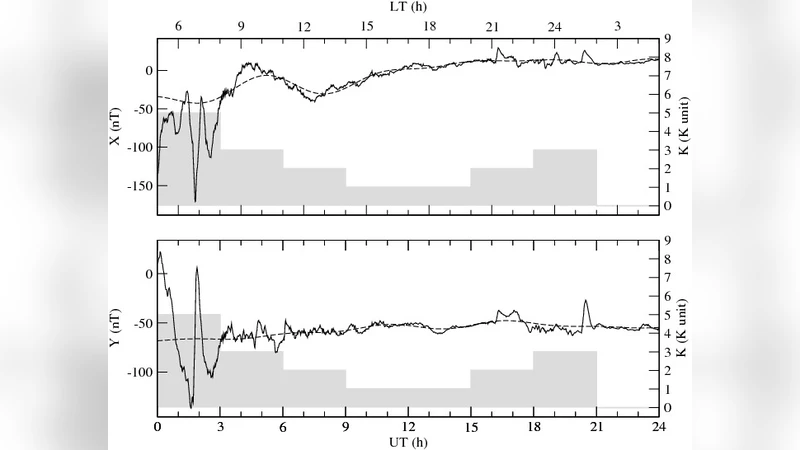
연구자는 동일한 기간 동안 두 종류의 데이터 시계열을 준비했다. 첫 번째는 1초 간격으로 기록된 고해상도 데이터이며, 두 번째는 1분 간격으로 다운샘플링된 데이터이다. 두 데이터 모두 동일한 보정 절차와 외부 잡음 제거 과정을 거쳤으며, 각 3시간 구간마다 변동값을 계산하고 이를 K지수로 변환했다.
결과 분석에서는 활동 수준을 저활동(L‑level)과 중간활동(M‑level)으로 구분했다. 저활동 구간에서는 1초 데이터와 1분 데이터 간 K지수 차이가 거의 없었으나, 변동값 자체는 1초 데이터가 평균 5 % 정도 더 큰 값을 보였다. 이는 미세한 급변이 거의 없기 때문에 샘플링 간격 차이가 크게 영향을 미치지 않음을 의미한다. 반면 중간활동 구간에서는 1초 데이터가 1분 데이터에 비해 평균 0.3~0.5 K단위 높은 값을 기록했으며, 변동값 차이는 12 %에 달했다. 특히 급격한 폭풍 전후 구간에서는 1초 데이터가 포착한 순간 최대 변동이 1분 데이터에서는 평균적으로 20 % 이하로 축소되어, K지수 등급이 낮게 평가되는 현상이 뚜렷했다.
통계적으로는 두 데이터 세트 간 상관계수가 0.96으로 높았지만, 잔차 분석에서 활동이 강할수록 오차가 증가하는 비선형 패턴이 확인되었다. 이는 K지수 산출에 사용되는 변동값이 로그 스케일로 매핑되는 특성상, 작은 변동 차이가 높은 등급 구간에서 큰 등급 차이로 확대될 수 있음을 시사한다.
연구자는 이러한 결과를 바탕으로, 고활동 시기에는 최소 1초 샘플링이 필요하다고 제언한다. 또한 기존에 1분 샘플링을 기준으로 구축된 장기 K지수 기록과 비교할 때, 고해상도 데이터 기반 재계산이 과거 기록의 재해석을 요구할 가능성을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기