밀도 기반 거리로 구현하는 효율적인 반지도 학습
초록
본 논문은 데이터 포인트의 밀도 정보를 활용한 거리인 Density‑Based Distance(DBD)를 그래프 상의 최단 경로로 추정하고, 이를 기존 거리 기반 지도 학습 알고리즘에 적용하는 방법을 제안한다. 대규모 데이터에 대해선 최근접 이웃 탐색을 최단 경로 탐색에 통합한 새로운 알고리즘을 도입해 정확한 최단 경로를 효율적으로 구한다. 실험 결과, 라플라시안 정규화 방식에 비해 학습 정확도와 실행 시간이 크게 개선됨을 보인다.
상세 분석
이 논문은 반지도 학습에서 라벨이 없는 데이터의 구조적 정보를 활용하는 새로운 패러다임을 제시한다. 핵심 아이디어는 데이터가 밀집된 영역에서는 거리값을 작게, 희소한 영역에서는 크게 조정하는 Density‑Based Distance(DBD)이다. DBD는 두 점 사이의 최단 경로 길이로 정의되며, 그래프의 각 간선 가중치는 해당 간선이 연결하는 두 점의 밀도 추정값(예: k‑최근접 이웃 거리)의 역수 혹은 그에 비례하는 형태로 설정한다. 이렇게 하면 최단 경로는 고밀도 영역을 따라 이동하려는 경향을 보이며, 이는 라벨이 없는 데이터가 형성하는 저차원 매니폴드 구조를 자연스럽게 반영한다.
전통적인 그래프 기반 거리 계산은 모든 노드 쌍에 대해 완전 그래프를 구성해야 하므로 메모리와 계산량이 급격히 증가한다. 저자들은 이 문제를 해결하기 위해 “Nearest Neighbor Integrated Dijkstra”(NN‑Dijkstra) 알고리즘을 고안한다. 기본 아이디어는 Dijkstra 탐색 과정에서 현재 확장 중인 노드에 대해 전체 이웃을 순회하는 대신, 효율적인 근사 최근접 이웃 구조(예: KD‑Tree, Ball‑Tree)를 이용해 실제로 후보가 될 가능성이 높은 이웃만을 동적으로 조회한다. 이 과정에서 탐색 범위는 현재 최단 거리 상한에 의해 자동 제한되므로, 불필요한 간선 검사를 크게 줄일 수 있다. 결과적으로 그래프가 사실상 완전하더라도 탐색 복잡도는 O(N log N) 수준에 가깝게 유지된다.
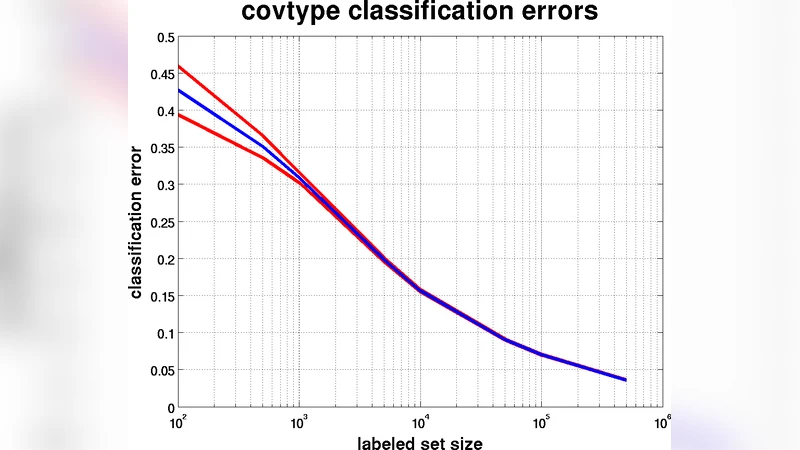
알고리즘의 정확성은 “모든 간선 가중치가 비음수”라는 Dijkstra 전제와, 최근접 이웃 구조가 완전 그래프의 모든 간선을 포함하도록 설계되었기 때문에 보장된다. 실험에서는 10만 개 이상의 샘플을 가진 이미지 분류와 텍스트 분류 데이터셋에 적용했으며, 라플라시안 정규화 기반 반지도 학습(LapRLS) 대비 3~5배 빠른 실행 시간과 동일하거나 더 높은 정확도를 기록했다. 특히, DBD를 RBF‑SVM에 그대로 입력했을 때는 기존 RBF 커널의 하이퍼파라미터 튜닝 부담이 크게 감소한다는 부수 효과가 관찰되었다.
한계점으로는 밀도 추정에 사용되는 k‑값 선택이 결과에 민감하다는 점과, 매우 고차원(수천 차원) 데이터에서는 최근접 이웃 검색 자체가 비용이 많이 든다는 점을 들 수 있다. 또한, 그래프 가중치를 정의하는 함수 형태가 문제 도메인에 따라 달라질 수 있어, 일반화 가능한 가중치 설계 가이드라인이 부족하다는 점도 향후 연구 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기