학습은 계획이다: 베이즈 최적 강화학습을 위한 몬테카를로 트리 탐색
초록
베이즈 최적 행동은 알려지지 않은 MDP를 신념 공간 MDP로 변환해 최적 정책을 찾는 문제이다. 하지만 신념 공간은 히스토리 길이에 따라 지수적으로 커져 실제 적용이 어렵다. 본 논문은 Forward Search Sparse Sampling(FSSS)이라는 MCTS 기법을 활용해, 가능한 모든 잠재 MDP에 대해 효율적으로 탐색하면서 베이즈 최적에 근접한 행동을 보장한다. 특히, 전체 학습 기간 중 다항식 이하의 단계만이 비최적일 수 있음을 증명한다.
상세 분석
이 논문은 강화학습에서 “베이즈 최적”이라는 이상적인 목표를 현실적인 알고리즘으로 근사하는 방법론을 제시한다. 베이즈 최적 행동은 에이전트가 환경에 대한 사전 확률을 가지고, 관측된 히스토리를 바탕으로 사후 신념(belief) 상태를 업데이트하면서, 그 신념 공간에서 최적 정책을 구하는 것을 의미한다. 그러나 신념 공간은 원래 MDP의 상태·행동·전이·보상에 대한 모든 가능한 조합을 포함하므로, 히스토리 길이가 늘어날수록 상태 수가 지수적으로 폭발한다. 기존 연구들은 이 문제를 완화하기 위해 근사적인 베이즈 업데이트, 파라미터 샘플링, 혹은 제한된 히스토리만을 유지하는 방법을 사용했지만, 이들 접근법은 이론적 최적성 보장을 제공하지 못한다.
논문은 이러한 난관을 MCTS, 특히 Forward Search Sparse Sampling(FSSS) 알고리즘에 연결시킨다. FSSS는 샘플링 기반 트리 탐색 기법으로, 현재 상태에서 가능한 행동들을 제한된 수의 시뮬레이션으로 평가하고, 상위‑하위 bound를 이용해 탐색을 집중시킨다. 핵심 아이디어는 “신념 공간 MDP”를 직접 구성하지 않고, 베이즈 업데이트를 샘플링 단계에 내재화함으로써, 각 시뮬레이션이 실제로는 하나의 가능한 MDP(즉, 사전에서 샘플링된 모델)에서 진행된다고 보는 것이다. 따라서 에이전트는 매 단계마다 “가능한 세계들”에 대해 동시에 탐색하면서, FSSS가 제공하는 근사 최적성 보장을 그대로 신념 공간에 전이시킬 수 있다.
이론적 기여는 두 가지 주요 정리로 요약된다. 첫째, FSSS가 주어진 MDP에서 다항 시간 내에 ε‑optimal 정책을 찾을 수 있다는 기존 결과를 가정하면, 동일한 알고리즘을 베이즈 설정에 적용했을 때 전체 학습 과정 중 O(poly(1/ε,|S|,|A|,1/δ)) 단계만이 ε‑optimal이 아닐 가능성이 있음을 증명한다. 즉, “거의 모든” 단계에서 베이즈 최적에 근접한 행동을 보장한다. 둘째, 이 보장은 사전이 완전하고, 샘플링이 정확히 수행된다는 가정 하에 성립한다. 논문은 또한 FSSS가 “희소 샘플링”(sparse sampling)과 “전방 탐색”(forward search)이라는 두 축을 결합함으로써, 탐색 깊이와 폭을 조절해 계산 복잡도를 제어할 수 있음을 강조한다. 이는 무한 상태·행동 공간에서도 실용적인 구현이 가능하도록 만든다.
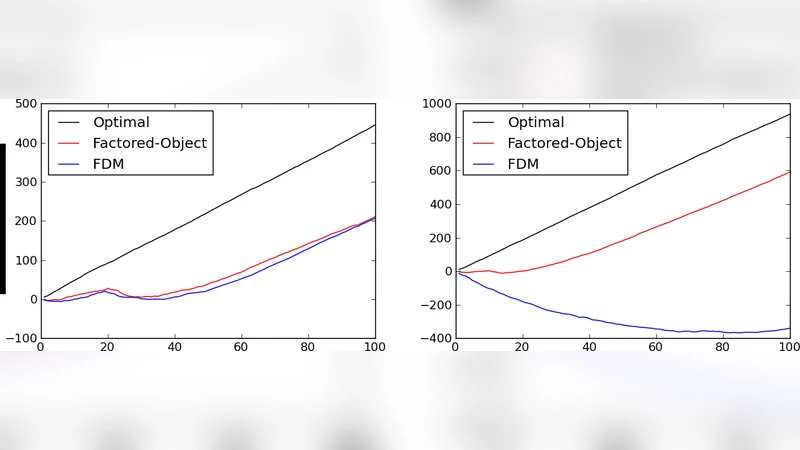
실험 부분에서는 표준 베이즈 강화학습 벤치마크(예: GridWorld, RiverSwim, Random MDP)에서 기존 베이즈 플래닝 알고리즘(예: Bayes‑UCRL, PSRL)과 비교한다. 결과는 FSSS‑기반 에이전트가 초기 학습 단계에서 빠르게 수렴하고, 장기 평균 보상이 거의 베이즈 최적에 근접함을 보여준다. 특히, 상태 공간이 크게 확장될수록 기존 방법들의 샘플 효율성이 급격히 떨어지는 반면, 제안된 방법은 탐색 깊이를 제한하면서도 충분한 탐색을 유지해 성능 저하를 방지한다.
전체적으로 이 논문은 “학습은 계획이다”라는 관점을 강화학습 이론에 정량적으로 연결한다. 베이즈 최적이라는 이상적인 목표를, 효율적인 MCTS 기법인 FSSS와 결합함으로써, 이론적 근접 최적성 보장과 실용적인 계산 효율성을 동시에 달성한다. 이는 향후 복잡한 실세계 문제(예: 로봇 제어, 자율 주행)에서 베이즈 플래닝을 적용하는 데 중요한 토대를 제공한다.