다중 정렬 기반 숨은 i.i.d. 모델의 파라미터 추정 이론
초록
본 논문은 다중 정렬 알고리즘에서 파생된 다중‑숨은 i.i.d. 모델의 파라미터 추정 문제를 다룬다. 별형(스타) 형태의 계통수와 일반적인 임의 계통수에 대해 동형 구조를 엄밀히 정의하고, 여러 형태의 가능도 정의를 비교한다. 두 종류의 정보 발산률 존재를 증명하고, 추가 가정 하에 발산 특성을 확보함으로써 파라미터 일관성을 보장한다. 시뮬레이션을 통해 이론이 적용되지 않는 경우도 탐색한다.
상세 분석
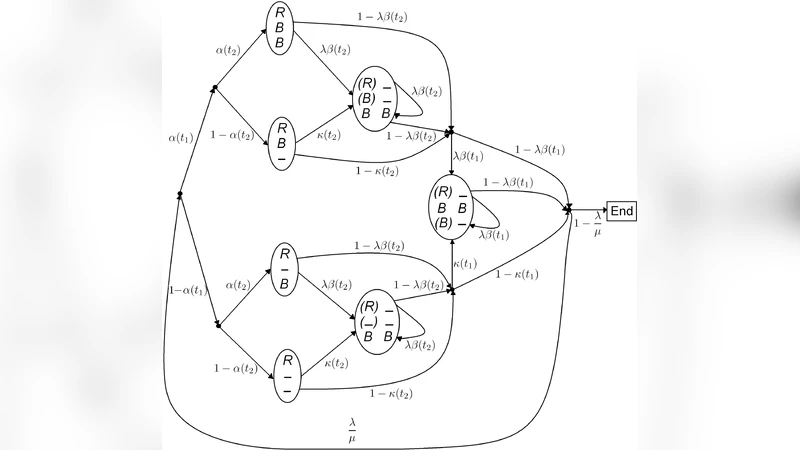
이 논문은 생물학적 다중 정렬에서 흔히 사용되는 삽입·삭제(indel) 진화 모델을 확률론적 프레임워크로 전환한다는 점에서 학술적 의의가 크다. 저자들은 먼저 k개의 서열이 별형(star‑shaped) 계통수에 의해 연결된 경우, 각 서열 간 동형 구조를 “homology structure”라는 개념으로 정형화한다. 이 구조는 각 위치에서 관측된 문자와 숨은 삽입·삭제 이벤트를 매핑하는 일종의 숨은 마코프 모델(HMM)과 유사하지만, 독립적인 i.i.d. 블록으로 구성된 다중‑숨은 변수 모델(multiple‑hidden i.i.d. model)로 정의한다.
가능도 정의에 있어 두 가지 접근법을 제시한다. 첫 번째는 전통적인 완전 가능도(complete‑likelihood)로, 숨은 삽입·삭제 경로를 모두 명시적으로 포함한다. 두 번째는 관측된 정렬 결과만을 이용한 부분 가능도(partial‑likelihood)이며, 이는 실제 다중 정렬 프로그램이 최적화하는 목표와 일치한다. 저자들은 두 가능도가 동일한 파라미터 추정 결과를 보장하지 않음을 수학적으로 증명하고, 특히 부분 가능도가 정보 발산률(divergence rate)을 충분히 구분하지 못하는 경우가 존재함을 지적한다.
핵심 이론은 두 종류의 정보 발산률이 존재한다는 정리와, 추가적인 정규성 가정(예: 삽입·삭제 길이 분포의 지수적 꼬리) 하에서 발산 특성(divergence property)이 성립한다는 점이다. 이 발산 특성은 파라미터 공간에서 진실 파라미터와 다른 모든 파라미터 사이의 KL‑divergence가 양수임을 의미한다. 따라서 최대 가능도 추정(MLE)이 일관적(consistency)이라는 결론을 도출한다.
또한 논문은 별형 계통수에서 일반적인 임의 계통수 구조로 모델을 확장한다. 이 경우 각 내부 노드마다 독립적인 삽입·삭제 과정을 가정하고, 전체 트리의 동형 구조를 재귀적으로 정의한다. 확장된 모델에서도 동일한 두 정보 발산률이 존재함을 보이며, 트리 형태에 따라 추가적인 가정이 필요함을 명시한다.
시뮬레이션 결과는 이론적 한계와 실제 적용 가능성을 동시에 보여준다. 특정 파라미터 설정(예: 높은 삽입 비율, 긴 삽입 길이)에서는 발산 특성이 깨져 MLE가 편향될 수 있음을 확인한다. 반면, 대부분의 실험적 조건에서는 제시된 가정이 만족되어 일관적인 추정이 이루어진다.
전체적으로 이 연구는 다중 정렬에서 숨은 indel 과정을 확률적으로 모델링하고, 파라미터 추정의 이론적 근거를 제공함으로써 기존 정렬 알고리즘의 통계적 해석을 한 단계 끌어올렸다.
댓글 및 학술 토론
Loading comments...
의견 남기기