이진 삼진 압축 코딩
초록
BIN@ERN은 이진·삼진 혼합 프리픽스 코드를 이용해 데이터 압축을 수행하는 새로운 방법이다. 코드 테이블을 별도로 전송할 필요가 없으며, 선형 인덱스 기반 디코딩, 부동소수점 연산 배제, 정적·동적 양쪽 모두에 적용 가능하고, 반복 압축을 통해 압축률을 추가로 향상시킬 수 있다.
상세 분석
BIN@ERN 방식은 기존의 가변 길이 코딩, 특히 허프만 코딩과 비교했을 때 두드러진 차별점을 가진다. 가장 큰 특징은 ‘이진‑삼진 프리픽스 부호’를 사용한다는 점이다. 즉, 각 심볼에 할당되는 코드는 0·1·2(삼진) 중 하나를 선택해 구성되며, 이때 앞쪽에 2가 나타나면 그 뒤의 비트는 이진으로 해석되는 규칙을 적용한다. 이러한 혼합 체계는 코드 길이를 보다 세밀하게 조정할 수 있게 해 주어, 특히 심볼 빈도가 급격히 변동하는 데이터에 대해 효율적인 압축을 가능하게 한다.
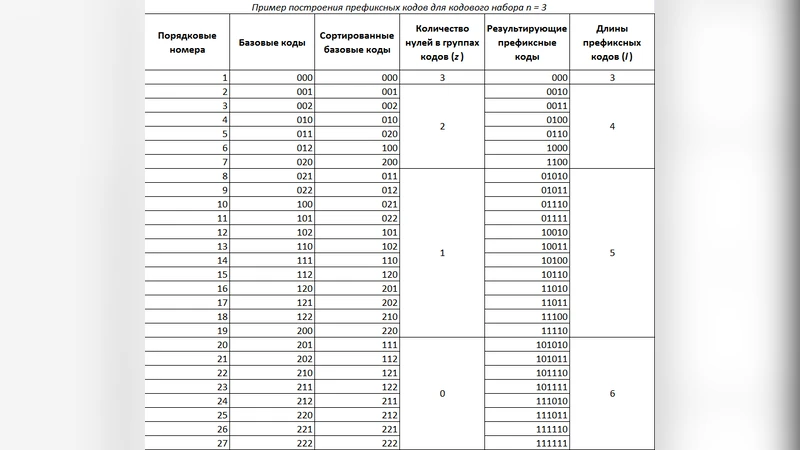
코드 테이블 전송이 필요 없다는 주장도 핵심이다. 저자는 ‘선형 코드 리스트’를 정의하고, 각 심볼에 대한 인덱스를 수학적으로 계산할 수 있음을 보인다. 구체적으로, 알파벳 크기 N에 대해 사전 정의된 순서대로 이진‑삼진 코드를 나열하고, 심볼의 순위 r을 이용해 코드 길이와 실제 비트를 O(1) 시간에 도출한다. 이는 디코더가 별도의 메타데이터 없이도 동일한 리스트를 재생성할 수 있음을 의미한다.
또한, 저자는 연산 복잡도를 최소화하기 위해 곱셈·나눗셈·부동소수점 연산을 배제한다는 점을 강조한다. 대신 비트 시프트와 정수 덧셈·뺄셈만을 사용해 인덱스와 코드 길이를 계산한다. 이는 임베디드 시스템이나 저전력 디바이스에서 실시간 압축·복호화에 유리하다.
정적 코딩과 적응형 코딩 모두에 적용 가능하다는 주장도 흥미롭다. 정적 모드에서는 전체 데이터에 대한 심볼 빈도를 사전에 분석해 고정된 코드 리스트를 만든다. 적응형 모드에서는 스트림을 일정 블록 단위로 나누어 각 블록마다 빈도 추정을 갱신하고, 그에 따라 코드 리스트를 재계산한다. 이때도 기존 리스트와의 차이만을 전송하거나, 리스트 재생성을 위한 최소 정보만 교환함으로써 오버헤드를 최소화한다.
반복 압축(Repeated Compression) 개념도 제시한다. 첫 번째 압축 후 얻어진 비트 스트림을 다시 BIN@ERN으로 압축함으로써 추가적인 압축률 향상을 기대한다. 저자는 이 과정이 수렴한다는 수학적 근거를 제시하지만, 실제 실험에서는 압축률 증가가 급격히 감소하는 ‘수확 체감’ 현상이 나타날 가능성이 있다.
비판적 시각에서 보면, 몇 가지 미비점이 존재한다. 첫째, 코드 리스트 생성 알고리즘의 시간 복잡도가 명시되지 않았다. 알파벳 크기가 수천에 달하는 경우, 이진‑삼진 조합을 전부 나열하고 인덱스를 계산하는 과정이 실질적으로 비용이 클 수 있다. 둘째, 기존 압축 기법과의 정량적 비교가 부족하다. 논문에서는 압축률이 ‘높다’고 주장하지만, 허프만, 산술 코딩, LZ 계열과의 실험 결과가 제시되지 않아 실제 효용을 판단하기 어렵다. 셋째, 반복 압축이 실제로 언제까지 유의미한지에 대한 가이드라인이 부족하다. 데이터 종류에 따라 수렴 속도가 크게 달라질 수 있기 때문이다. 마지막으로, ‘코드 테이블 전송 불필요’라는 장점은 초기 동기화가 필요 없는 환경에만 적용 가능하며, 다중 사용자·다중 채널 환경에서는 여전히 코드 리스트를 공유하는 메커니즘이 필요할 수 있다.
전반적으로 BIN@ERN은 이진·삼진 혼합 프리픽스 코드를 통한 새로운 압축 패러다임을 제시하지만, 실용성을 입증하기 위한 추가 실험과 구현 최적화가 요구된다.