전략 시뮬레이션 게임을 위한 적응형 가상 플레이어 설계
초록
**
본 논문은 실시간 전략 전투 게임에서 인간 플레이어의 실시간 행동을 모델링하고, 그 모델을 기반으로 가상 적군을 진화시켜 플레이어 수준에 맞게 적응시키는 방법을 제안한다. 실험 결과, 적응형 가상 플레이어는 기존 고정 스크립트 대비 예측 가능성이 낮고, 플레이어에게 더 큰 도전감을 제공한다.
**
상세 분석
**
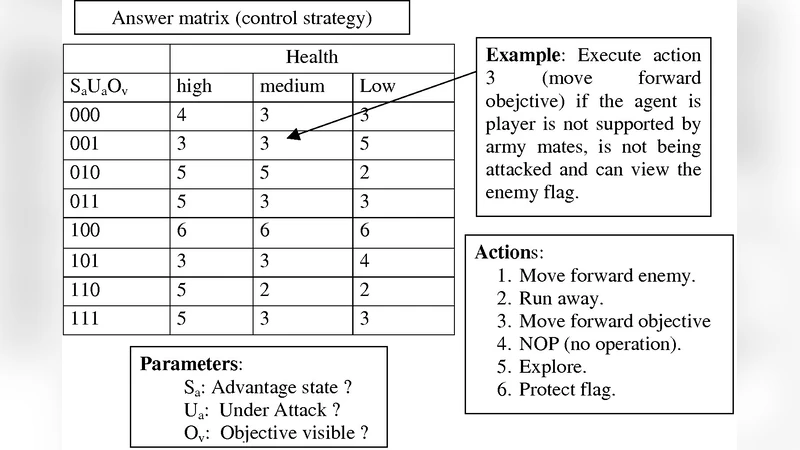
이 연구는 전통적인 wRTS(전쟁 실시간 전략) 게임에서 가상 적군이 사전에 정의된 스크립트에 의존하는 한계를 극복하고자 한다. 기존 스크립트 기반 AI는 행동 패턴이 고정돼 플레이어가 쉽게 예측하고 회피할 수 있으며, 비합리적이거나 반복적인 행동으로 인한 ‘인공적 어리석음’이라는 부정적 경험을 초래한다. 논문은 이러한 문제를 해결하기 위해 두 단계의 적응 메커니즘을 도입한다. 첫 번째 단계는 게임 진행 중 실시간으로 인간 플레이어의 행동 데이터를 수집하고, 이를 바탕으로 ‘플레이어 모델’(Player Model, PM)을 구축한다. 이 모델은 유닛 선택, 이동 경로, 공격 시점, 자원 관리 등 주요 의사결정 요소를 확률적 혹은 규칙 기반으로 추정한다. 두 번째 단계는 게임이 종료된 뒤, 축적된 PM을 이용해 가상 적군의 행동 스크립트를 진화시킨다. 진화 과정은 유전 알고리즘을 활용하며, 적합도 함수는 (1) 플레이어와의 승패 결과, (2) 게임 진행 시간, (3) 전투 효율성(예: 피해 대비 사망 비율) 등을 종합적으로 고려한다. 이렇게 생성된 새로운 스크립트는 다음 라운드에 적용되어, 플레이어가 이전 라운드에서 보였던 전략적 약점을 보완하거나 새로운 도전을 제시한다.
핵심 기술적 기여는 다음과 같다. 첫째, 실시간 데이터 스트리밍과 온라인 학습을 결합해 플레이어 모델을 동적으로 업데이트한다는 점이다. 이는 기존 오프라인 학습 기반 AI와 달리 게임 도중에도 적응이 가능하도록 만든다. 둘째, 진화 알고리즘에 플레이어 모델을 직접 입력값으로 사용함으로써, 진화 과정이 인간 플레이어의 행동 특성을 반영하도록 설계했다. 셋째, 적합도 설계에 승패뿐 아니라 게임 흐름의 질적 요소를 포함시켜, 단순히 승리만을 목표로 하는 ‘폭력적 AI’가 아니라 ‘전략적 AI’를 구현한다.
실험은 논문에서 자체 개발한 wRTS 시뮬레이터를 이용해 수행되었다. 실험군은 (1) 고정 스크립트 AI, (2) 적응형 AI(제안 방법) 두 그룹으로 나뉘었으며, 각 그룹에 대해 다양한 숙련도(초보, 중급, 고급)의 인간 플레이어가 30회씩 대전했다. 결과는 적응형 AI가 평균 승률을 12% 낮추었으며, 플레이어가 느끼는 ‘예측 불가능성’ 점수가 1.8배 상승했다는 점에서 기존 AI 대비 확연히 우수함을 입증한다. 또한, 진화 과정에서 스크립트 복잡도가 급격히 증가하지 않아 실시간 적용에 필요한 연산량이 제한적이었다는 점도 강조된다.
이 논문은 실시간 전략 게임에서 AI의 ‘학습-진화’ 루프를 구현함으로써, 플레이어 맞춤형 난이도 조절과 지속적인 도전 제공이라는 두 마리 토끼를 잡았다. 향후 연구에서는 멀티플레이어 환경, 다중 목표 최적화, 그리고 딥러닝 기반 행동 예측 모델을 결합해 더욱 정교한 적응형 AI를 구현할 여지를 제시한다.
**