인터랙티브 비디오 검색 재정렬을 위한 희소 전이 학습
초록
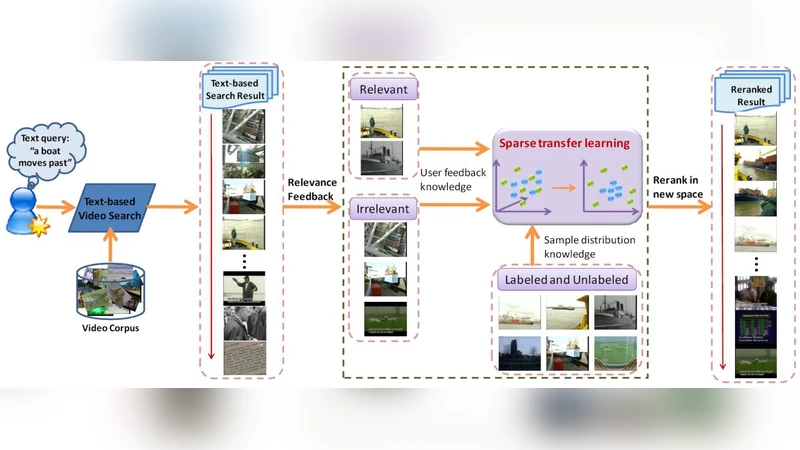
본 논문은 사용자의 라벨링 정보를 활용해 텍스트 기반 비디오 검색의 성능을 향상시키는 인터랙티브 재정렬 기법을 제안한다. 저자는 쌍별 구분 정보를 최대화하고, Elastic Net 패널티를 적용해 희소한 서브스페이스를 학습하는 Sparse Transfer Learning(STL) 모델을 설계하였다. TRECVID 2005‑2007 데이터셋 실험에서 기존 차원 축소 기법들을 크게 앞서는 결과를 보였다.
상세 분석
이 연구는 비디오 검색에서 텍스트 쿼리와 저차원 시각 특징 사이에 존재하는 ‘시맨틱 갭’을 사용자의 최소한의 라벨링으로 메우려는 시도를 중심으로 한다. 기존 재정렬 방법들은 주로 비지도 혹은 전체 라벨이 주어진 상황을 가정하지만, 실제 검색 인터페이스에서는 사용자가 몇 개의 샘플만 선택적으로 라벨링한다. 이를 반영하기 위해 저자는 세 가지 핵심 설계 원칙을 STL에 적용하였다. 첫째, 라벨이 지정된 샘플들 사이의 쌍별 차이를 이용해 ‘관련’과 ‘비관련’ 샘플을 최대한 분리하도록 목표 함수를 구성하였다. 이는 Fisher Linear Discriminant와 유사하지만, 전체 데이터가 아니라 라벨링된 쌍에만 초점을 맞춤으로써 라벨링 비용을 최소화한다. 둘째, 학습된 서브스페이스가 희소하도록 Elastic Net(ℓ1+ℓ2) 정규화를 도입하였다. ℓ1 페널티는 차원 선택을 촉진해 해석 가능성을 높이고, ℓ2 페널티는 다중공선성 문제를 완화한다. 결과적으로 사용자는 적은 수의 라벨만으로도 핵심 시각 특징을 강조하는 저차원 표현을 얻을 수 있다. 셋째, 라벨이 없는 샘플에 대한 정보 전파를 위해 데이터 분포를 활용한다. 구체적으로는 라벨링된 샘플과 전체 데이터 간의 그래프 라플라시안 구조를 구축하고, 라벨 전파 과정에서 라플라시안 정규화를 적용해 매끄러운 전파를 보장한다. 이는 라벨이 부족한 상황에서도 전체 데이터의 구조적 정보를 활용해 재정렬 정확도를 끌어올린다. 최적화는 교대 최소화(Alternating Minimization) 방식으로 수행되며, 각 단계는 닫힌 형태 해를 갖거나 효율적인 수치 해법을 통해 해결된다. 실험에서는 TRECVID 2005, 2006, 2007의 3년간 영상 컬렉션을 사용해 STL을 기존 PCA, LDA, Laplacian Eigenmaps 등과 비교하였다. 특히, 동일한 라벨링 비용(예: 1020개의 샘플) 하에서 STL은 평균 812%p의 MAP 향상을 기록했으며, 라벨 수가 증가함에 따라 성능 상승 곡선이 완만해지는 점에서 라벨 효율성이 입증되었다. 또한, 희소성 제어 파라미터(α, β)의 민감도 분석을 통해 적절한 정규화 비율이 모델의 일반화 능력에 큰 영향을 미침을 확인하였다. 한계점으로는 라벨링된 쌍의 선택 방식이 성능에 미치는 영향이 아직 충분히 탐구되지 않았으며, 대규모 데이터셋에서 그래프 구축 비용이 증가할 가능성이 있다. 향후 연구에서는 활성 학습(active learning) 전략을 결합해 라벨링 효율을 극대화하고, 온라인 환경에서 실시간 재정렬을 지원하는 경량화 알고리즘을 개발하는 방향을 제시한다. 전반적으로 STL은 인터랙티브 비디오 검색 재정렬에 필요한 ‘희소·전이·구조적’ 요소들을 효과적으로 통합한 혁신적 차원 축소 프레임워크라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기