분산 CPU GPU 아키텍처를 활용한 대규모 천문 데이터 분석 및 시각화
초록
본 논문은 테라바이트 규모의 천문 데이터 처리를 위해 CPU와 GPU를 결합한 분산 프레임워크를 제안한다. 공유‑분산 메모리 모델, 마스터‑슬레이브 MPI 통신, CUDA 스트림을 이용해 대용량 스펙트럼 큐브의 실시간 볼륨 렌더링을 수행하고, 128 GPU·64노드 환경에서 초당 2.5 테라볼셀 처리량을 달성하였다. 또한 서비스형 소프트웨어(SaaS) 모델을 통해 천문학자들의 접근성을 높이고 총소유비용을 절감하는 방안을 논의한다.
상세 분석
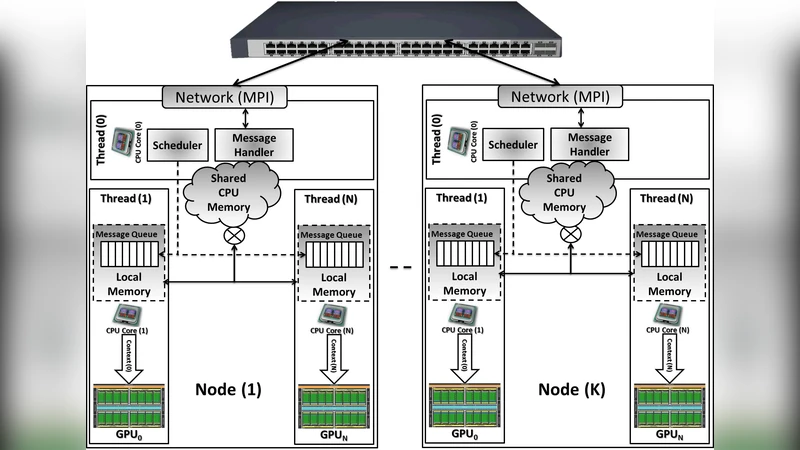
이 연구는 현재 천문 관측 시설이 생성하는 테라바이트‑페타바이트 규모 데이터의 메모리·연산 한계를 극복하기 위해, 다중 코어 CPU와 다수의 GPU를 결합한 이종 분산 시스템을 설계하였다. 핵심은 각 노드 내 GPU를 전용 CPU 코어가 관리하도록 하여, 데이터 전처리·GPU 커널 호출·후처리를 순차적이면서도 비동기적으로 수행하도록 한 점이다. 마스터 스레드가 전역 통신을 담당하고, 슬레이브 스레드가 로컬 공유 메모리와 세마포어를 통해 안전하게 데이터 교환을 수행한다는 구조는 전통적인 MPI‑OpenMP 혼합 모델을 확장한 형태라 할 수 있다. 특히 NVIDIA CUDA 4.0의 Unified Virtual Addressing을 활용해 CPU‑GPU 간 주소 공간을 통합함으로써, 복제 없이 직접 메모리 접근이 가능해 메모리 복사 비용을 크게 감소시켰다. 또한 다중 스트림(Execution Queues)을 이용해 데이터 I/O와 GPU 연산을 겹치게 함으로써, 메모리 대역폭과 네트워크 대역폭을 효율적으로 활용하였다.
성능 평가에서는 4 GB부터 204 GB까지의 스펙트럼 큐브를 128개의 GPU(노드당 2개)와 64개의 노드에서 처리했으며, 프레임당 처리 속도는 33 fps에서 55 fps 사이를 기록했다. 데이터 전송량은 출력 해상도(메가픽셀/GPU)와 직접 연관되며, 두 단계(로컬 공유 메모리, 전역 MPI)로 분할된 통신 구조 덕분에 전체 전송량을 최소 50 % 절감했다. 최종적으로 초당 2.5 테라볼셀(테라볼륨) 처리량을 달성했으며, 이는 동일 문제를 CPU만으로 수행했을 때 대비 노드 수를 크게 줄일 수 있음을 의미한다.
논문은 또한 이러한 프레임워크를 SaaS 형태로 제공함으로써, 천문학자들이 별도 슈퍼컴퓨터를 구축하지 않아도 웹 기반 클라이언트(QT5)로 실시간 시각화와 분석을 수행할 수 있음을 강조한다. 이는 특히 SKA와 같은 차세대 전파망원경이 생성할 1 TB 규모의 스펙트럼 큐브를 다루는 데 있어, 데이터 파티셔닝·다중 패스 연산(예: 중앙값, 표준편차) 등을 효율적으로 수행할 수 있는 기반이 된다. 향후 프라이빗 클라우드와 연계한 온디맨드 자원 공유 모델을 도입하면, 총소유비용(TCO)을 낮추고 다중 사용자 환경에서도 확장성을 유지할 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기