네트워크 구조 탐색: 커뮤니티를 넘어선 그룹 발견
초록
본 논문은 인간의 시각적 패턴 인식 능력과 컴퓨터의 고속 연산을 결합한 시각 분석 프레임워크를 제안한다. 노드의 다차원 속성 공간을 무작위 2차원 투영으로 시각화하고, 사용자가 직접 그룹 구분을 입력하면 이를 기반으로 자동으로 구조적 그룹을 식별한다. 기존 커뮤니티 탐지 기법이 놓치기 쉬운, 연결 밀도 외의 다양한 구조적 특성을 가진 그룹을 효과적으로 찾아낸다.
상세 분석
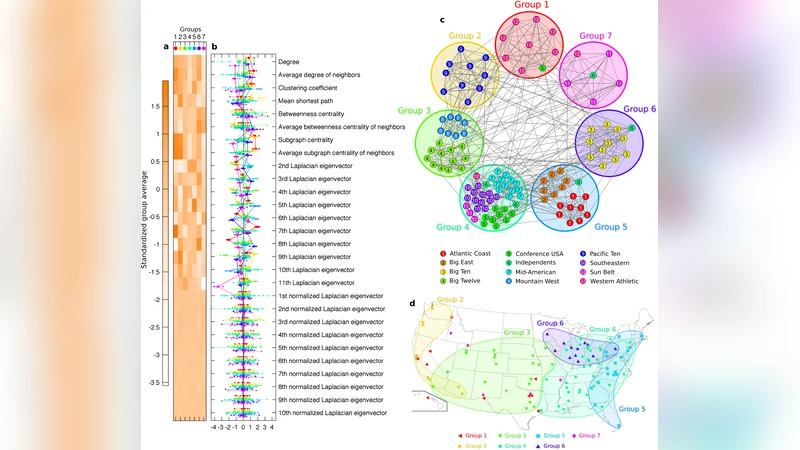
이 연구는 “구조적 그룹(structural groups)”이라는 개념을 도입한다. 구조적 그룹은 노드가 내부·외부 연결 밀도 차이뿐 아니라 중심성, 스펙트럼 특성 등 다차원 속성을 공유하는 집합으로 정의된다. 논문은 28개의 노드 속성을 선택해 각 노드를 ℝ^28 공간의 점으로 매핑한다. 핵심 아이디어는 고차원 공간에서의 군집이 저차원 투영(특히 2차원)에서 명확히 구분될 가능성을 활용하는 것이다. 무작위 투영을 여러 번 수행하고, 각 투영마다 사용자가 “그룹이 보인다” 혹은 “보이지 않는다”를 판단한다. 사용자가 투영에서 인식한 그룹 구분은 그래픽 인터페이스를 통해 각 노드에 그룹 번호가 할당되는 형태로 기록된다.
투영 L번에 대해 각 노드 i는 할당 벡터 a(i) = (a₁(i),…,a_L(i))를 갖는다. 이 벡터는 사용자가 여러 투영에서 해당 노드를 어느 그룹에 넣었는지를 나타낸다. 이후 단일 연결 계층 군집(single‑linkage hierarchical clustering)을 Hamming 거리(벡터 간 차이 개수) 기반으로 적용해 최종적인 구조적 그룹을 도출한다. 군집을 자르는 임계값 d는 “Q_g drop‑off”라는 품질 지표의 급격한 감소 지점을 이용해 자동 선택한다. Q_g는 그룹 간 평균 거리와 그룹 내부 평균 분산의 비율을 정규화한 값으로, 군집 수 K에 대한 편향을 보정한다.
방법론적 강점은 두 가지이다. 첫째, 인간의 시각적 인지는 고차원 데이터의 복잡한 패턴을 직관적으로 포착할 수 있어, 전통적인 알고리즘이 놓치는 비선형·다중 속성 구분을 보완한다. 둘째, 무작위 투영을 다수 사용함으로써 “effective dimension”이 낮은 경우에도 높은 확률로 그룹을 드러낼 수 있다. 논문은 Gaussian 클러스터 예시를 들어, 투영 7개만으로도 구분 실패 확률을 0.001 이하로 낮출 수 있음을 보인다.
실험에서는 6개의 실제 네트워크(카라테 클럽, 정치 서적, 단어 연관, 대학 풋볼, 과학자 협업, 질병 네트워크)를 대상으로 적용했다. 각 네트워크는 27개의 구조적 그룹으로 분류되었으며, 필요한 최소 속성 수(p_d)는 215개에 달했다. 특히, 일부 네트워크는 라플라시안 고유벡터만으로도 그룹이 구분되었지만, 대부분은 복합적인 속성 조합이 필요했다.
벤치마크 테스트에서는 두 그룹으로 구성된 합성 네트워크에서 기존 커뮤니티 탐지 알고리즘(모듈러리티 최적화, 혼합 모델 등)과 K‑means를 비교했다. 조정 랜드 지수(Adjusted Rand Index) 기준으로, 인간이 참여한 시각 분석 방법이 p_out ≤ 0.15 구간에서 거의 완벽한 성능을 보였으며, p_out이 커져도 상대적으로 높은 정확도를 유지했다. 자동화된 K‑means가 투영에 적용된 경우에도 인간 주도 방식보다 성능이 낮았지만, 직접 고차원 속성에 적용한 K‑means보다 훨씬 우수했다. 이는 다중 투영과 인간 직관이 결합될 때 얻어지는 시너지 효과를 입증한다.
제한점으로는 인간 참여가 필요하므로 대규모 네트워크(수십만 노드 이상)에서는 인터페이스 설계와 작업 효율성이 문제될 수 있다. 또한, 속성 선택이 사전 정의돼 있어, 중요한 속성이 누락될 경우 그룹 탐지가 어려워진다. 향후 연구에서는 자동 속성 중요도 평가와 군집 결과의 통계적 검증을 결합해 완전 자동화에 가까운 시스템을 구축하는 방향이 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기