편향 없는 풀 기반 능동 학습 알고리즘 UPAL
UPAL은 풀 기반 능동 학습에서 위험의 무편향 추정량을 최소화하는 새로운 알고리즘이다. 선형 분류기와 제곱 손실을 가정하면, UPAL은 지수 가중 평균 포레캐스터와 동등함을 보이며, 무작위 행렬 이론을 이용해 선형 진실 가설일 때 일관성을 증명한다. 실험 결과는 Vowpal Wabbit 구현 및 기존 배치 능동 학습 알고리즘보다 높은 정확도와 뛰어난 확장성을 보여준다.
저자: Ravi Ganti, Alex, er Gray
**1. 서론 및 배경**
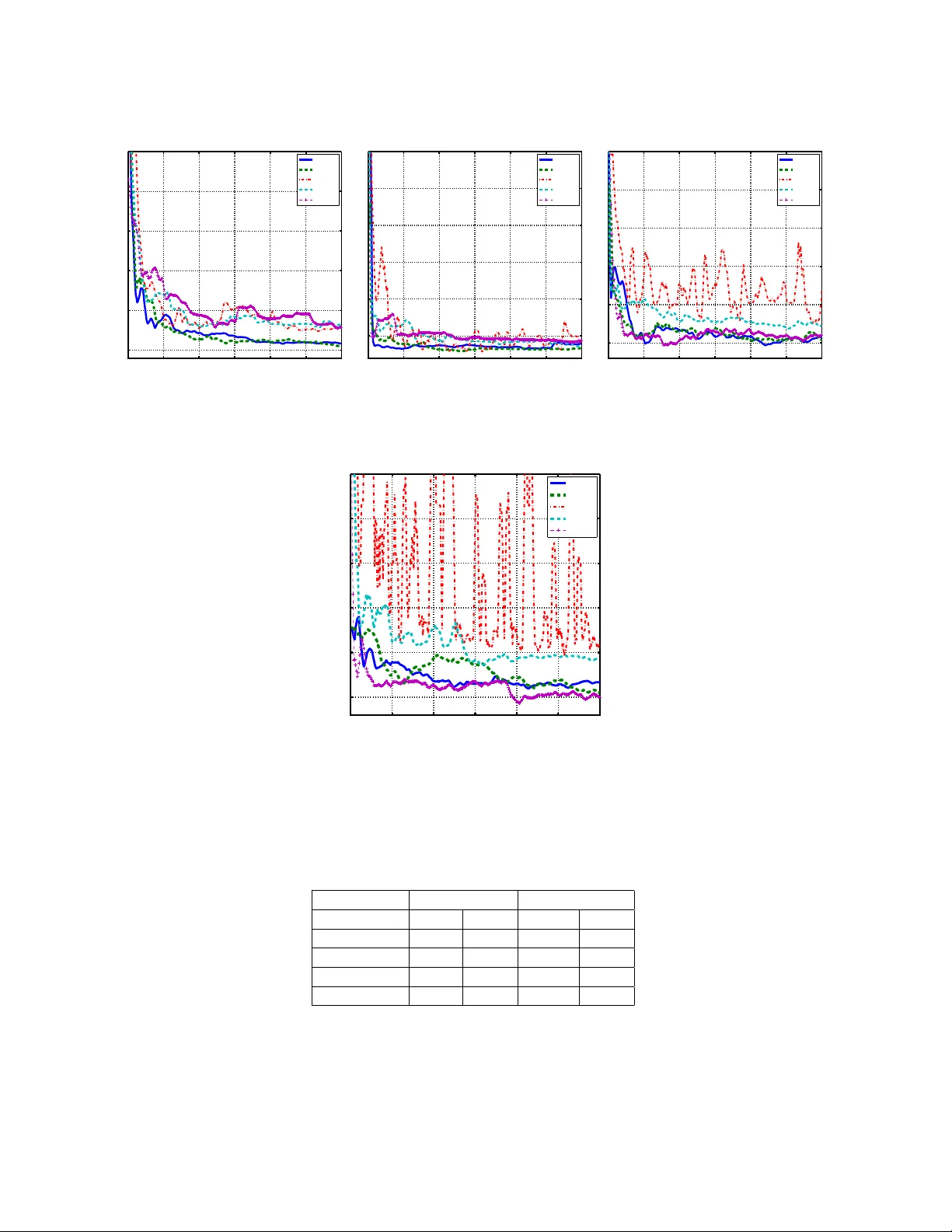
능동 학습은 라벨링 비용이 높은 상황에서 최소한의 라벨만으로 높은 정확도를 얻고자 하는 학습 패러다임이다. 크게 멤버십 쿼리(MQ), 스트림 기반, 풀 기반 세 종류가 존재한다. 풀 기반은 사전에 대규모 비라벨 데이터 풀 P를 확보하고, 제한된 예산 B 내에서 가장 정보량이 큰 샘플을 선택해 라벨을 요청한다. 기존 풀 기반 방법은 불확실성(예: 엔트로피) 기반 샘플링을 사용했지만, 샘플링 분포와 실제 데이터 분포 사이의 차이를 보정하지 못해 비효율적인 라벨링이 발생한다.
**2. UPAL 알고리즘 설계**
UPAL은 매 라운드 t마다 전체 풀에 확률 분포 pₜ를 할당하고, 그 분포에 따라 하나의 샘플을 선택한다. 선택된 샘플이 이전에 라벨링된 적이 있으면 기존 라벨을 재사용하고, 없으면 오라클 O에 질의한다. 중요도 가중치 Qₜᵢ·pₜᵢ (Qₜᵢ∈{0,1})를 사용해 현재까지 라벨된 데이터에 대한 위험 ˆLₜ(h) = (1/n)∑ᵢ∑_{τ≤t} Q_τᵢ p_τᵢ φ(yᵢ, hᵀxᵢ) 를 계산한다. Theorem 1은 이 추정량이 진정한 위험 L(h)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기