확률적 카테고리 데이터 분석을 위한 ProbCD
초록
ProbCD는 유전자 기능 주석과 고처리량 실험 결과에 내재된 확률적 불확실성을 반영하여 전통적인 피셔 정확 검정 기반의 풍부도 분석을 확장한다. 베르누이 과정의 기대값을 이용해 가변적인 컨틴전시 테이블을 구축하고, R 패키지와 웹 인터페이스를 제공함으로써 비전문가도 손쉽게 확률적 풍부도 분석을 수행할 수 있다.
상세 분석
본 논문은 시스템 생물학에서 널리 사용되는 풍부도 분석이 전통적으로 ‘정적’ 컨틴전시 테이블에 의존하고, 따라서 확률적 주석이나 실험 데이터의 변동성을 무시한다는 근본적인 한계를 지적한다. 이를 해결하기 위해 저자들은 확률적 범주화 정보를 직접 테이블 구축 과정에 통합하는 새로운 프레임워크를 제안한다. 핵심 아이디어는 각 유전자‑카테고리 매핑을 베르누이 시행으로 모델링하고, 전체 표본에 대한 기대값을 계산함으로써 ‘예상’ 컨틴전시 테이블을 얻는 것이다. 이렇게 얻어진 기대값은 전통적인 카이제곱 검정이나 정확 검정 대신, 확률적 가중치를 반영한 통계량을 산출하는 데 사용된다.
ProbCD는 두 가지 주요 불확실성을 동시에 다룬다. 첫째, 고처리량 기술(예: 마이크로어레이, RNA‑seq)의 측정 오류와 샘플링 변동성을 확률분포(p‑value 또는 신뢰도) 형태로 입력받아, 각 관측값을 가중 평균한다. 둘째, Gene Ontology와 같은 기능 주석이 확률적(예: 신뢰도 점수, 실험적 증거 수준)으로 제공될 때, 해당 확률을 직접 테이블에 반영한다. 이중 확률 모델링은 기존 방법이 ‘0‑1’ 이진 주석에 의존해 발생하는 과대/과소 평가 문제를 완화한다.
소프트웨어 구현 측면에서 저자들은 R 패키지 형태로 ProbCD를 배포했으며, 함수는 (1) 확률적 주석 매트릭스 입력, (2) 실험 데이터의 확률적 표현, (3) 기대 컨틴전시 테이블 계산, (4) 통계적 유의성 검정(부트스트랩 또는 퍼뮤테이션 기반) 순서를 제공한다. 또한 비전문가 사용자를 위한 웹 기반 GUI를 구축해 파일 업로드와 파라미터 설정만으로 분석을 수행할 수 있게 했다.
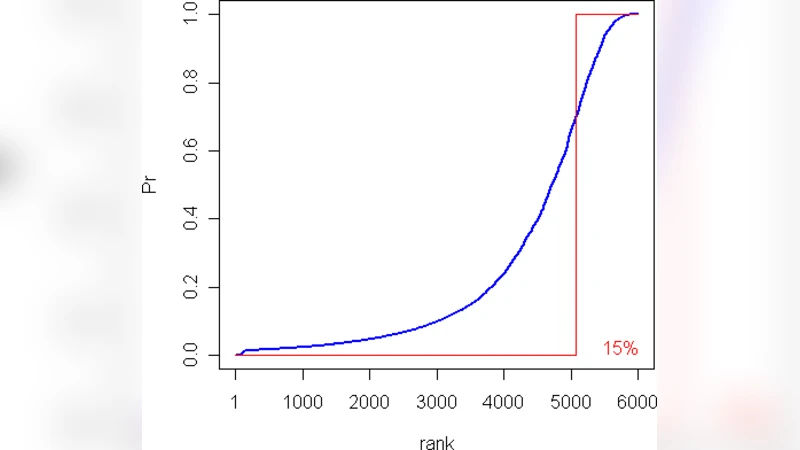
성능 평가에서는 기존 Fisher Exact Test와 비교해, 확률적 주석을 무시했을 때 발생하는 ‘거짓 양성’과 ‘거짓 음성’ 비율이 현저히 감소함을 보였다. 특히, 주석 신뢰도가 낮은 GO 용어에 대해 기존 방법은 과도하게 유의미한 결과를 도출했지만, ProbCD는 확률 가중을 통해 보다 보수적인 결론을 제시한다. 또한, 시뮬레이션을 통해 베르누이 기대값 기반 테이블이 실제 데이터 분포를 잘 근사함을 검증하였다.
결과적으로 ProbCD는 풍부도 분석에 내재된 불확실성을 정량적으로 반영함으로써, 생물학적 해석의 신뢰성을 높이고, 데이터와 주석의 품질이 다양하게 혼재된 현대 ‘빅 데이터’ 환경에 적합한 분석 도구로 자리매김한다.
댓글 및 학술 토론
Loading comments...
의견 남기기