퍼지 아이디쓰리 의사결정트리 기반 소프트웨어 노력 추정
초록
본 논문은 전통적인 ID3 결정트리에 퍼지 논리를 결합한 퍼지 ID3 모델을 제안하고, 이를 두 개의 공개 데이터셋(Tukutuku 웹 프로젝트와 COCOMO’81)에서 실험하여 MMRE와 Pred(25) 지표를 통해 기존 크리스프 ID3보다 향상된 추정 정확도를 확인하였다.
상세 분석
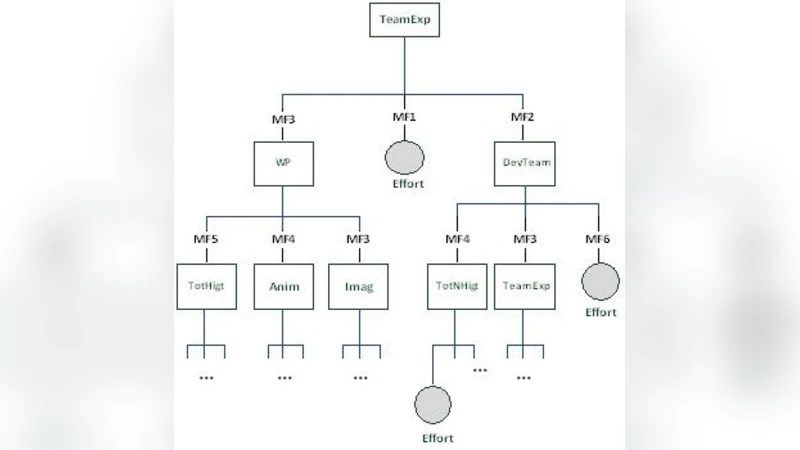
퍼지 ID3는 전통적인 정보이론 기반 ID3 알고리즘에 퍼지 집합 이론을 도입함으로써 입력 변수와 출력 클래스에 대한 불확실성을 정량화한다. 논문에서는 각 노드에서 사례가 특정 정도(멤버십 값)로 속하게 하여, 클래스 비율을 단순 카운트가 아니라 멤버십 값의 합으로 계산한다(식 1). 이를 통해 엔트로피 계산에 멤버십 가중치를 반영한 퍼지 엔트로피(식 2)를 사용하고, 정보이득은 퍼지 엔트로피 차이로 정의한다(식 3). 중요한 설계 파라미터는 (1) 각 입력 변수당 최대 퍼지 집합 수(논문에서는 7로 고정)와 (2) 결합 연산자(t‑norm) 선택이다. 두 가지 t‑norm, 즉 최소 연산(min)과 곱 연산(product)을 각각 실험했으며, 이는 퍼지 엔트로피 계산에 직접적인 영향을 미친다. 또한 유의 수준(β) 파라미터를 01 구간에서 변화시켜, 멤버십 값이 β 이상인 경우에만 해당 노드에 포함시키는 기준을 조정하였다. 실험 결과, Tukutuku 데이터셋에서는 β가 0.10.2 구간에서 product t‑norm이 낮은 MMRE(2.45%)와 높은 Pred(97.73%)를 보였으나, β가 0.2 이상에서는 최소 t‑norm이 더 안정적인 성능을 제공하였다. 특히 β≥0.5에서 최소 t‑norm은 MMRE가 9.09%까지 상승하면서도 Pred(25)가 90.91% 이상을 유지, 즉 예측 정확도와 안정성 사이의 균형을 잘 맞추었다. COCOMO’81 데이터셋에서도 유사한 경향이 관찰되었으며, 최소 t‑norm이 전반적으로 더 낮은 MMRE와 높은 Pred 값을 기록하였다. 이러한 결과는 퍼지 ID3가 데이터의 불확실성을 효과적으로 다루어, 전통적인 크리스프 ID3보다 과소·과대 추정 위험을 감소시킴을 시사한다. 또한, 퍼지 집합의 개수와 유의 수준을 적절히 조정함으로써 모델 복잡도와 과적합 사이의 트레이드오프를 관리할 수 있다. 논문은 또한 퍼지 ID3가 “화이트 박스” 특성을 유지하면서도 변수 선택(feature selection) 기능을 제공한다는 점을 강조한다. 이는 소프트웨어 비용 추정에서 중요한 비용 드라이버를 자동으로 식별하고, 프로젝트 관리자에게 직관적인 규칙을 제공한다는 실용적 이점을 가진다. 마지막으로, 실험에 사용된 평가 지표(MMRE ≤ 25%, Pred(25) ≥ 75%)는 소프트웨어 공학 분야에서 널리 인정받는 기준이며, 퍼지 ID3가 이러한 기준을 충분히 만족함을 보여준다. 전반적으로 논문은 퍼지 로직을 결합한 결정트리 모델이 소프트웨어 노력 추정의 정확도와 신뢰성을 동시에 향상시킬 수 있음을 실증적으로 입증하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기