단백질 국소 구조 변화를 포착하는 새로운 D2 코딩 방법
초록
본 논문은 백본 구조를 16개의 문자로 구성된 D2 코드로 변환해 단백질의 국소적인 컨포메이션 변화를 정량적으로 식별하는 방법을 제안한다. 기존 구조 알파벳이나 2차 구조 기반 기법보다 이산적인 변화를 더 민감하게 탐지하며, HIV‑1 프로테아제 변이와 NMR 모델 집합에서 우수한 성능을 보였다.
상세 분석
이 연구는 단백질 백본을 5‑잔기 단위로 추출한 뒤, 각 잔기의 Cα 좌표를 기반으로 ‘접힌 사면체(tetrahedron) 연속’을 구성한다. 사면체는 네 개의 짧은 변과 두 개의 긴 변(길이 비율 √3/2)으로 정의되며, 인접 사면체가 공유하는 면을 통해 연속을 만든다. 사면체의 ‘gradient’는 현재 사면체가 이전 사면체와 공유하지 않는 변의 방향으로 정의되고, 연속 내에서 gradient가 바뀔 때마다 1, 유지될 때 0을 부여한다. 이렇게 얻어진 0/1 이진 문자열을 길이 5인 블록마다 32진수(0‑9, A‑V)로 변환해 각 Cα 위치에 할당하면, 단백질 전체를 1차원 문자열(D2 코드)로 표현한다.
핵심적인 차별점은 기존 구조 알파벳이 클러스터링 기반으로 ‘대표 구조’를 정의하는 반면, D2 코드는 실제 기하학적 변화를 직접 반영한다는 점이다. 따라서 미세한 굽힘, 비틀림, 국소적인 ‘U‑turn’ 회피 등 다양한 왜곡을 손실 없이 기록한다. 변형 탐지는 동일 단백질에 대한 여러 실험 모델(예: X‑ray 구조, NMR 모델, 돌연변이 구조) 간 D2 코드가 서로 다른 잔기에 대해 다중 코드를 가질 경우를 변수 부위로 정의한다.
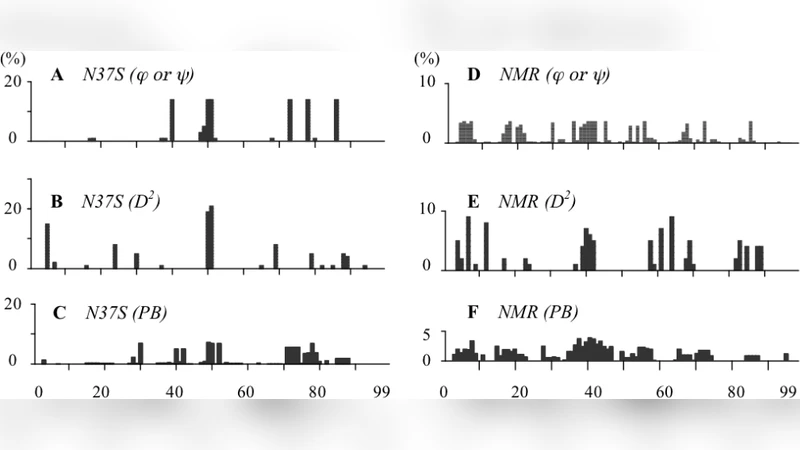
성능 평가는 세 가지 ‘골드 스탠다드’(ϕ/ψ 각도 변화 기준)와 기존 PB 코드, DSSP, ϕ/ψ 기반 방법과 비교하였다. 정확도(ACC), 민감도(SN), 특이도(SP), Matthews 상관계수(MCC)를 이용한 정량적 분석 결과, D2 코드는 ANGL(30° 이상 변화) 영역에서 가장 높은 정확도와 MCC를 기록했으며, ANGL_SUPP(변화가 존재하는 모든 잔기) 영역에서는 가장 높은 특이도를 보였다. 반면 PB 코드는 ANGL_CORE(극심한 변화) 영역에서 민감도가 가장 높았다.
또한 HIV‑1 프로테아제 N37S 변이 72개의 결정구조와 28개의 NMR 모델을 대상으로 실험했을 때, D2 코드는 변이 부위와 인접 루프의 미세한 구조 차이를 다른 방법보다 명확히 구분하였다. 특히 NMR 모델 간의 작은 좌표 변동을 반영해 다중 D2 코드가 나타나는 잔기를 정확히 식별함으로써, 용액 상태에서의 구조 다양성을 효과적으로 포착했다.
이 방법은 기존 구조 비교에 비해 구현이 간단하고, 일반적인 서열 정렬 알고리즘을 그대로 적용할 수 있다는 실용적 장점도 갖는다. 다만 사면체 모델링 과정에서 초기 정렬 및 회전 선택이 필요하며, 매우 긴 사슬(예: 대형 복합체)에서는 연속 길이에 따른 계산 비용이 증가할 수 있다. 향후 클러스터링 없이도 고차원 구조 특징을 추출하는 방향으로 확장 가능성이 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기