GPU 기반 락프리 흐름·매칭 알고리즘 구현
초록
본 논문은 Nvidia CUDA 환경에서 그리드 그래프의 최대 흐름을 풀기 위한 락프리 푸시‑리라벨 알고리즘과, 완전 이분 그래프의 가중 매칭을 해결하는 비용 스케일링 알고리즘을 각각 구현하고 성능을 평가한다. 두 알고리즘 모두 원자 연산을 활용해 스레드 동기화 없이 병렬화를 달성했으며, 전통적인 순차 알고리즘 대비 상당한 속도 향상을 보인다.
상세 분석
논문은 먼저 GPU 프로그래밍 모델인 CUDA 4.0의 기본 구조와 메모리 계층(전역, 공유, 레지스터, 캐시)을 상세히 설명하고, 병렬 구현 시 데이터 전송 비용을 최소화하기 위한 메모리 관리 전략을 제시한다. 흐름 문제에 대해서는 기존의 푸시‑리라벨 알고리즘을 기반으로 Hong의 락프리 버전을 채택했으며, 각 정점을 하나의 CUDA 스레드가 담당하도록 설계하였다. 여기서 핵심은 원자적 add/sub 연산을 이용해 잉여 용량과 초과 흐름을 동시에 업데이트함으로써 전역 동기화 없이 올바른 흐름 유지가 가능하도록 한 점이다. 또한, 전역 리라벨링과 갭 리라벨링이라는 두 가지 휴리스틱을 GPU 친화적으로 구현해 높이 값이 불필요하게 커지는 현상을 방지하고, BFS 기반 전역 리라벨링을 일정 주기마다 수행해 전체 실행 시간을 크게 단축시켰다.
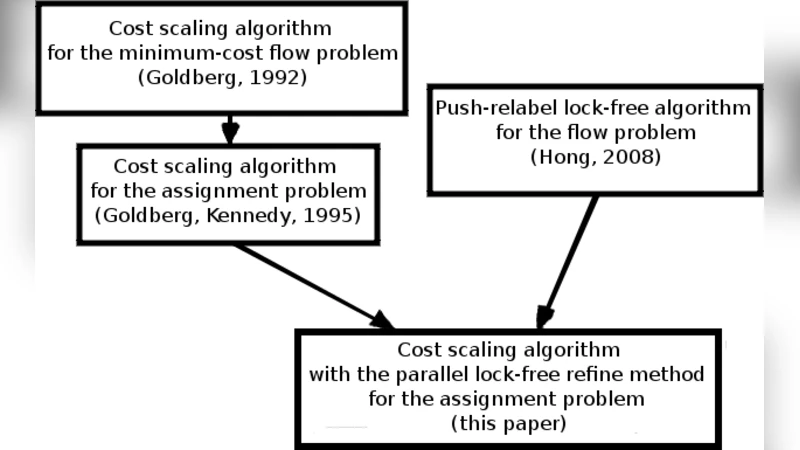
매칭 문제에서는 Goldberg 등(2,8,9)이 제안한 비용 스케일링 알고리즘을 차용하고, 그 내부에서 흐름을 계산하는 서브루틴으로 앞서 구현한 락프리 푸시‑리라벨을 재사용한다. 비용 스케일링 단계마다 ε‑optimal 흐름을 유지하기 위해 가격(p) 함수를 갱신하고, 감소된 비용 그래프에서 admissible edge만을 선택해 효율적인 푸시 연산을 수행한다. 이때도 원자 연산을 활용해 다중 스레드가 동시에 엣지 용량을 수정하도록 함으로써 충돌을 방지한다.
실험은 Nvidia GTX 560 Ti (Compute Capability 2.1)를 사용했으며, 그리드 그래프에 대한 최대 흐름 계산에서 기존 CPU 기반 구현 대비 10배 이상, 비용 스케일링 기반 매칭에서는 7배 이상의 속도 향상을 보고한다. 그러나 구현은 주로 정규 격자와 완전 이분 그래프에 초점을 맞추었고, 비정형 그래프나 메모리 요구량이 큰 경우에는 공유 메모리 활용이 제한적이며, 원자 연산에 의존하는 구조가 높은 스레드 경쟁을 일으킬 수 있다는 한계도 언급한다. 전체적으로 이 논문은 GPU에서 락프리 병렬화를 적용한 흐름·매칭 알고리즘의 설계 원칙과 실용적인 구현 방법을 제시함으로써 컴퓨터 비전 및 그래픽스 분야에서 대규모 최적화 문제를 해결하는 데 중요한 참고 자료가 된다.
댓글 및 학술 토론
Loading comments...
의견 남기기