다중인스턴스·다중라벨 학습의 새로운 패러다임
초록
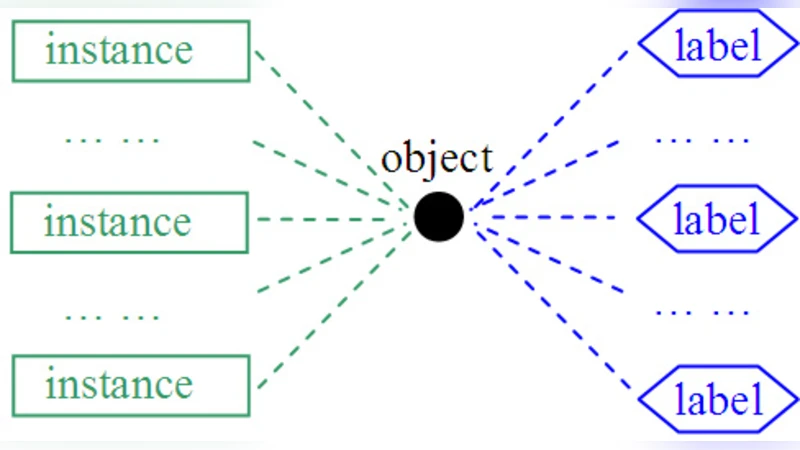
본 논문은 하나의 예제가 여러 인스턴스로 구성되고 동시에 다수의 라벨을 가질 수 있는 MIML(Multi‑Instance Multi‑Label) 프레임워크를 제안한다. 기존 학습 방식보다 복합 객체를 자연스럽게 표현할 수 있다. 저자는 MIML을 단순히 기존 학습기로 변환하는 MimicBoost·MimicSvm, 변환 과정에서 정보 손실을 보완하는 정규화 기반 D‑MimlSvm, 그리고 단일 인스턴스·단일 라벨 데이터를 MIML 형태로 변환하는 InsDif·SubCod 네 가지 알고리즘을 설계하고, 다양한 실험을 통해 성능 향상을 입증한다.
상세 분석
MIML 프레임워크는 “다중 인스턴스”와 “다중 라벨”이라는 두 축을 동시에 고려함으로써, 이미지의 여러 객체, 문서의 여러 주제, 유전자의 여러 기능 등 복합적인 의미를 내포한 데이터를 보다 충실히 모델링한다는 점에서 기존의 단일 인스턴스·단일 라벨(SI‑SL) 혹은 다중 인스턴스·단일 라벨(MI‑SL) 접근법을 확장한다. 논문은 먼저 MIML을 기존 학습기로 활용하기 위한 두 단계 변환 전략을 제시한다. MimicBoost은 각 라벨에 대해 독립적인 부스팅 분류기를 학습하고, 인스턴스 집합을 라벨별 “bag”으로 변환한다. MimicSvm은 라벨별 SVM을 동일하게 적용한다. 이러한 “degeneration” 방식은 구현이 간단하고 기존 라이브러리를 그대로 사용할 수 있다는 장점이 있지만, 인스턴스 간 상호작용과 라벨 간 상관관계를 무시하게 되어 정보 손실이 발생한다는 한계가 있다. 이를 보완하기 위해 저자는 정규화 기반 D‑MimlSvm을 고안한다. D‑MimlSvm은 라벨 공간과 인스턴스 공간을 동시에 고려하는 공동 정규화 목표함수를 정의하고, 라벨 간 상관관계를 커널 매트릭스로 모델링한다. 최적화는 구조화된 SVM 프레임워크를 이용해 풀며, 이 과정에서 다중 라벨의 공동 존재 확률과 인스턴스 집합의 대표성을 동시에 최적화한다. 실험 결과는 D‑MimlSvm이 단순 변환 기반 방법보다 일관되게 높은 정확도와 평균 F1 점수를 기록함을 보여준다.
또한 논문은 MIML이 실제 객체를 직접 관찰하기 어려운 상황에서도 유용함을 입증한다. InsDif는 기존 단일 인스턴스 데이터를 인위적으로 여러 인스턴스로 분할하고, 각 분할을 라벨과 연결해 MIML 형태로 변환한다. 이는 특히 이미지의 경우, 전체 이미지 대신 여러 패치(Region)로 나누어 학습함으로써 지역적 특징을 활용할 수 있게 한다. 반대로 SubCod는 단일 라벨 데이터를 다중 라벨 형태로 재구성한다. 라벨을 서브코드(예: 이진 비트열)로 표현하고, 각 비트를 별도의 라벨로 취급함으로써 라벨 간 잠재적 관계를 학습한다. 두 방법 모두 기존 SI‑SL 학습기에 비해 복합적인 의미를 포착하고, 특히 라벨이 희소하거나 객체가 복합적인 경우에 성능 향상을 보인다.
전반적으로 이 논문은 MIML이라는 새로운 데이터 표현 방식을 제시하고, 이를 구현하기 위한 알고리즘군을 체계적으로 정리한다. 변환 기반 접근법과 정규화 기반 직접 학습법을 모두 제공함으로써, 연구자와 실무자가 데이터 특성에 맞는 방법을 선택할 수 있게 한다. 또한 MIML이 기존 학습 패러다임을 대체하기보다 보완하는 역할을 할 수 있음을 실험적으로 증명한다는 점에서, 복합 객체 인식, 멀티라벨 텍스트 분류, 바이오인포매틱스 등 다양한 도메인에 적용 가능성이 높다.
댓글 및 학술 토론
Loading comments...
의견 남기기