전문가 식별과 사용자 다양성을 활용한 포크소노미 학습
초록
본 논문은 Flickr 사용자가 만든 개인 디렉터리(사플링)를 분석해 전문가와 초보자를 자동으로 구분하고, 전문가가 만든 고품질 주석을 가중치로 활용해 포크소노미(비공식 분류 체계)를 학습한다. 전문가 주석만으로도 정확하고 상세한 계층을 얻을 수 있지만, 초보자 주석을 함께 포함하면 전체적인 포괄성이 향상된다.
상세 분석
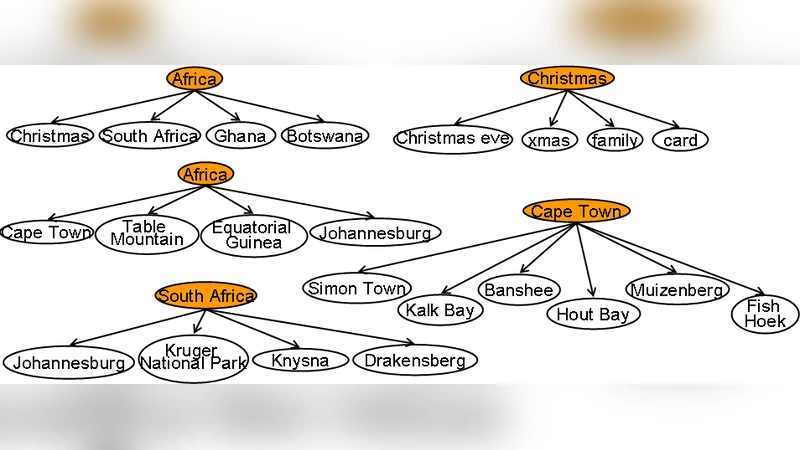
이 연구는 소셜 웹에서 사용자들이 생성하는 구조화된 주석, 즉 Flickr의 “컬렉션·세트” 계층을 ‘사플링(sapling)’이라 정의하고, 이를 기반으로 전문가를 식별하는 특성(feature) 집합을 설계한다. 사용자‑레벨 특성으로는 사플링 수(N), 태그 관계 수(Twig), 사플링 간 균형도(BU)와 다양성(Disparity) 등이 포함되며, 사플링‑레벨 특성은 깊이·폭을 결합한 ‘Sapling‑Variety’, 레벨별 균형을 측정하는 ‘Sapling‑Balance’, 루트 노드의 자식 분포가 얼마나 집중돼 있는지를 나타내는 ‘Root‑Diversity(30%, 50%, 70% 커버 비율)’ 등이다. 특히 루트‑다양성은 전문가가 의미 있는 상위 개념을 사용하고, 초보자는 ‘misc’, ‘other’와 같은 모호한 용어를 남발한다는 가정을 정량화한다.
전문가 식별 모델은 초기에 200명의 사용자를 인간 annotator가 라벨링한 데이터를 바탕으로 J48, Random Forest, LibSVM 등 세 가지 분류기를 학습한다. 이후 자기‑학습(self‑training) 절차를 통해 모델이 예측한 긍정 사례를 추가 라벨링하고 재학습함으로써 라벨링 비용을 최소화한다. 8번째 반복에서 LibSVM은 100% 정밀도, 88% 재현율, 93% F‑score를 달성했으며, 최종적으로 전체 데이터셋에서 66명의 전문가를 추출했다. 특성 중요도 분석 결과, ‘Sapling‑Depth’가 가장 높은 순위를 차지했으며, 그 다음으로 ‘Number of Leaves’, ‘Sapling‑Balance’ 등이 뒤따랐다. 이는 전문가가 깊고 균형 잡힌 계층 구조를 선호한다는 직관과 일치한다.
포크소노미 학습 단계에서는 기존 RAP(Relational Affinity Propagation) 알고리즘을 확장한다. RAP는 각 사플링을 노드 집합으로 보고, 친화도 행렬을 기반으로 exemplar(대표) 노드를 선택해 여러 사플링을 하나의 통합 트리로 클러스터링한다. 본 연구는 전문가 사플링에 높은 가중치를 부여하고, 초보자 사플링은 낮은 가중치로 처리함으로써 두 집단의 장점을 동시에 활용한다. 실험 결과, 전문가 가중치를 적용한 모델은 기존 RAP 대비 더 깊고 세부적인 분류 구조를 생성했으며, 초보자 데이터를 포함했을 때는 전체 개념 커버리지가 크게 증가했다. 즉, 전문가 지식은 정확도와 세밀함을, 초보자 지식은 포괄성을 제공한다는 결론에 도달한다.
이러한 접근은 소셜 미디어에서 발생하는 대규모 비구조화·반구조화 데이터에 대한 자동 지식 추출에 유용하며, 전문가와 비전문가의 주석을 적절히 조합함으로써 보다 신뢰성 높고 풍부한 온톨로지를 구축할 수 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기