자바 환경에서 계층적 군집을 통한 객체 참조 식별
초록
본 논문은 자바 프로그램의 실행 스택과 참조 스택을 이용해 함수 간 관계를 패턴 매트릭스로 변환하고, 유클리드 거리와 단일 연결(single linkage) 방식을 적용한 계층적 군집 분석으로 후보 객체 참조를 자동 식별하는 방법을 제안한다. 실험 결과는 참조 스택 관련 함수와 실행 스택 관련 함수를 각각 독립적인 클러스터로 구분함을 보여준다.
상세 분석
이 논문은 객체 지향 프로그래밍에서 객체 식별을 역공학적으로 지원하기 위해, 기존 절차형 언어에 적용된 스택·큐 기반 군집 기법을 자바 환경에 맞게 변형하였다. 핵심 아이디어는 두 종류의 스택(Reference Stack, Execution Stack)에서 제공되는 기본 연산들을 ‘패턴’으로 정의하고, 각 연산이 사용되는 구조체 필드와 매개변수 정보를 0·1 값으로 표현한 패턴 매트릭스를 만든 뒤, 이를 기반으로 유클리드 거리(Euclidean distance)를 계산해 유사도 행렬을 구성한다는 것이다.
패턴 매트릭스 구성 과정에서 저자는 각 연산을 행(row)으로, 연산이 속한 구조체 필드(R0~R5)와 매개변수 유형을 열(column)으로 두어 이진값을 채운다. 예를 들어 initRef는 R0과 R5에 해당하는 1을 갖고, ePush는 R2와 R4에 1을 갖는다. 이렇게 정의된 6×6 매트릭스는 각 연산 간의 속성 차이를 정량화하는 데 사용된다.
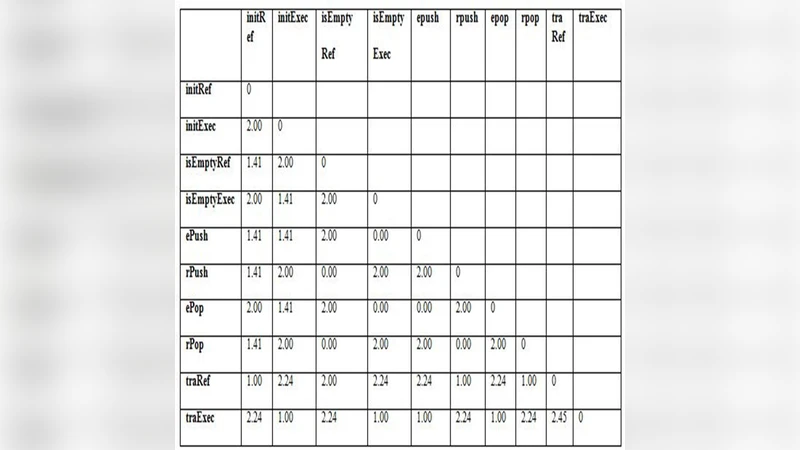
유클리드 거리 공식은 전통적인 형태인 √∑(x_ij−x_kj)² 를 그대로 적용했으며, 거리값이 0에 가까울수록 두 연산이 동일한 속성을 공유한다는 의미다. 초기 거리 행렬에서 가장 작은 거리(0.00)를 가진 쌍을 먼저 결합하고, 단일 연결(single linkage) 규칙을 이용해 클러스터 간 거리를 재계산한다. 단일 연결은 두 클러스터 중 가장 가까운 두 원소 사이의 거리를 새로운 클러스터 거리로 정의하므로, 군집이 진행될수록 ‘가장 유사한’ 연산들이 먼저 묶인다.
실험에서는 총 6개의 연산을 대상으로 5단계의 군집 과정을 수행했으며, 최종적으로 두 개의 주요 클러스터(C5, C6)가 도출되었다. C5는 initRef, traRef, isEmptyRef, rPush, rPop 등 참조 스택 관련 연산을 포함하고, C6는 initExec, traExec, isEmptyExec, ePush, ePop 등 실행 스택 관련 연산을 포함한다. 이는 제안된 방법이 스택 종류에 따라 연산을 효과적으로 구분한다는 점을 시사한다.
하지만 몇 가지 한계점도 존재한다. 첫째, 패턴 매트릭스를 0·1 이진값으로만 표현함으로써 연산 간 미세한 차이(예: 파라미터 값의 범위, 호출 빈도 등)를 반영하지 못한다. 둘째, 유클리드 거리 대신 코사인 유사도나 Jaccard 계수를 사용하면 이진 특성에 더 적합할 수 있다. 셋째, 군집 결과를 평가할 객관적인 메트릭(실루엣 점수, Dunn 지수 등)이 제시되지 않아, 클러스터의 품질을 정량적으로 판단하기 어렵다. 마지막으로, 실제 자바 프로그램에서 스택 연산을 추출하는 과정이 구체적으로 설명되지 않아, 적용 가능 범위가 제한적이다.
이러한 점들을 보완한다면, 제안된 계층적 군집 기법은 대규모 레거시 코드베이스에서 객체 참조를 자동으로 식별하고, 객체 지향 전환 작업을 지원하는 유용한 도구가 될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기