밀집 행렬 분해를 위한 하이브리드 정적·동적 스케줄링
초록
본 논문은 CALU와 같은 고성능 밀집 행렬 분해 알고리즘에 정적 스케줄링과 동적 스케줄링을 결합한 하이브리드 스케줄링 기법을 제안한다. 정적 부분은 데이터 지역성을 유지하고, 동적 부분은 부하 불균형을 보완한다. 48코어 AMD NUMA와 16코어 Intel Xeon 시스템에서 기존 정적·동적 방식 대비 최대 64%·8%의 성능 향상을 달성했으며, MKL·PLASMA 대비 110%·82%까지 가속을 기록하였다.
상세 분석
이 연구는 고성능 컴퓨팅 환경에서 밀집 행렬 LU 분해, 특히 통신 최소화를 목표로 하는 CALU 알고리즘에 적용 가능한 스케줄링 전략을 심도 있게 탐구한다. 기존의 완전 정적 스케줄링은 데이터 지역성을 최적화하지만, 실행 중 발생하는 미세한 성능 변동(예: OS 인터럽트, 메모리 대역폭 변동)으로 인해 코어가 유휴 상태에 빠지는 현상이 관찰되었다. 반대로 완전 동적 스케줄링은 작업이 준비되는 즉시 큐에서 꺼내 실행함으로써 부하 균형을 보장하지만, 작업 큐 접근에 따른 오버헤드와 캐시 친화성이 저하되어 메모리 접근 지연이 크게 늘어난다.
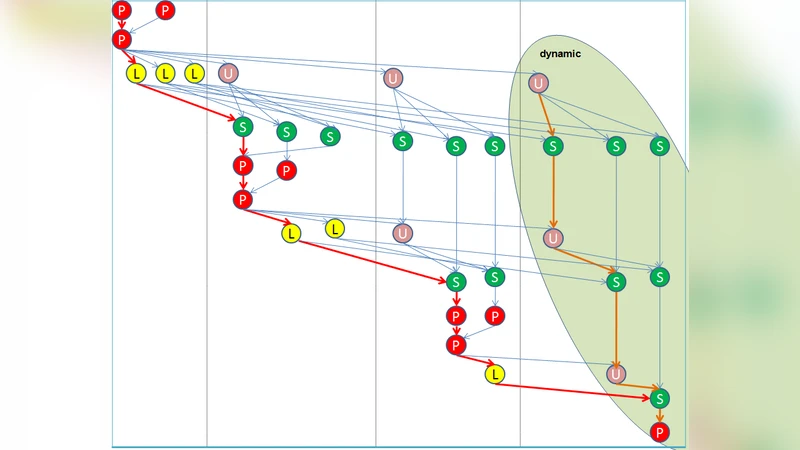
논문은 이러한 상충 관계를 해소하기 위해 작업 의존성 그래프(DAG)를 두 구역으로 분할한다. 초기 N_static 패널에 속하는 작업은 2‑차원 블록 사이클릭 배분을 이용해 정적으로 할당하고, 핵심 경로에 해당하는 P, L, U, S 작업을 우선적으로 각 스레드에 고정한다. 이는 데이터가 로컬 캐시에 머무를 확률을 높이고, 정적 부분에서 발생하는 스케줄링 비용을 최소화한다. 남은 패널에 대해서는 전역 공유 큐를 이용해 동적으로 작업을 할당한다. 이때 동적 할당 비율(percentage of dynamic tasks)은 하드웨어 특성(NUMA 거리, 메모리 대역폭)과 입력 행렬 크기에 따라 튜닝 가능하도록 설계되었다.
실험에서는 두 가지 데이터 레이아웃(전통적인 열 우선, 블록 사이클릭, 2‑레벨 블록) 모두에 대해 하이브리드 스케줄링이 유의미한 성능 향상을 보였다. 특히 48코어 AMD Opteron NUMA 시스템에서 정적 대비 30%~64%의 개선을 기록했으며, 이는 정적 스케줄링이 초래하는 코어 유휴 현상을 동적 파트가 효과적으로 메꿔준 결과이다. 16코어 Intel Xeon에서는 정적·동적 모두와 비교해 8% 정도의 개선을 보였는데, 이는 코어 수가 적어 동적 오버헤드가 상대적으로 크게 작용하지 않기 때문이다. 또한, MKL(인텔 Math Kernel Library)과 PLASMA와 비교했을 때, 하이브리드 구현은 각각 110%·82% 및 30%~45% 정도의 추가 가속을 달성했다.
이론적 분석 파트에서는 작업 그래프의 크리티컬 패스 길이와 동적 작업 큐 대기 시간을 모델링해, 동적 비율이 일정 임계값을 초과하면 오버헤드가 급격히 증가한다는 점을 증명한다. 따라서 최적의 동적 비율은 시스템의 메모리 계층 구조와 작업량에 따라 선형적으로 조정될 수 있음을 제시한다.
전체적으로 이 논문은 정적·동적 스케줄링을 단순히 혼합하는 것이 아니라, 작업 의존성을 기반으로 정적 구간을 명확히 정의하고, 동적 구간을 최소한의 오버헤드로 유지함으로써 데이터 지역성과 부하 균형을 동시에 달성한다는 점에서 기존 연구와 차별화된다. 이러한 접근은 CALU에 국한되지 않고, QR, Cholesky, LDLᵀ 등 다른 블록 기반 밀집 행렬 분해에도 적용 가능하다는 잠재력을 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기