텍스트 스테가노그래피 통계 분석과 탐지 기법
초록
**
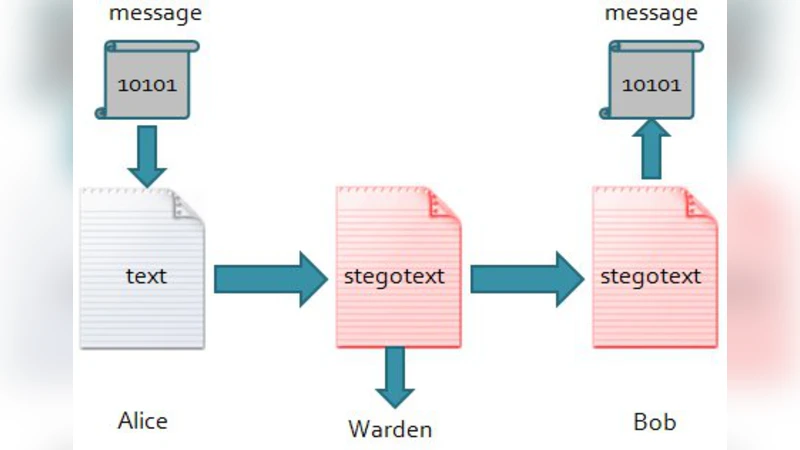
본 논문은 텍스트를 은폐 매체로 활용하는 다양한 스테가노그래피 기법을 정리하고, 이들에 대한 통계 기반 스테가노분석 방법들을 비교·평가한다. 특히 공간, 동의어 치환, 문법 생성, 번역 변형 등 네 가지 주요 은닉 방식과 SVM, 압축, 엔트로피 등 통계적 탐지 기법의 성능을 실험 결과와 함께 제시한다.
**
상세 분석
**
논문은 텍스트 스테가노그래피를 크게 구문 기반, 의미 기반, 언어 생성 기반, 번역 기반 네 종류로 구분한다. 구문 기반 방법은 공백 삽입이나 철자 오류와 같이 눈에 띄지 않는 물리적 포맷을 이용하지만, 이중 공백이나 비정상 철자 패턴이 쉽게 탐지될 수 있다. 의미 기반 방법은 동의어 사전을 활용해 단어를 교체함으로써 비트 정보를 숨기며, 사전 규모와 품질에 크게 의존한다. 실제 구현(T‑Lex)에서는 문맥 부조화와 장르 불일치가 빈번히 발생해 자연스러운 텍스트 생성에 한계가 있다. 언어 생성 기반은 문법 규칙이나 마코프 체인, Nicetext·Texto와 같은 시스템을 이용해 완전한 문장을 자동 생성한다. 이 접근은 텍스트 길이에 비해 숨길 수 있는 정보량이 크지만, 생성된 문장이 의미 없이 무의미하게 되는 부작용이 있다. 번역 기반 스테가노그래피는 동일 의미의 다중 번역 후보 중 하나를 선택해 비트를 인코딩한다. 원문과 번역문 사이의 변형 폭이 크기 때문에 탐지가 어려운 장점이 있다.
스테가노분석 측면에서는 통계적 특성을 활용한 여러 방법이 제시된다. 첫째, SVM 기반 분류기는 단어 빈도, 공백 비율, 문자 분포 등 메타 특징을 학습해 높은 정확도를 달성한다(예: Nicetext 99.61 %). 둘째, 압축 기반 탐지는 은닉 메시지가 컨테이너의 엔트로피를 증가시켜 압축 효율을 저하시키는 현상을 이용한다. 실험에서는 400 바이트 이상 텍스트에서 99.98 % 이상의 탐지율을 기록한다. 셋째, 엔트로피와 단어 거리 분산을 결합한 특징은 번역 기반 스테가노그래피에 특히 효과적이며, 10 KB~20 KB 텍스트에서 97 %~99 %의 정확도를 보인다. 또한, 오류율(FP 38.6 %, FN 15.1 %)이 높은 일부 방법은 실용성이 떨어진다. 전반적으로 통계적 접근이 대부분의 텍스트 스테가노그래피를 높은 확률로 식별할 수 있음을 확인한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기