약물과 의료조건 간 관계 탐색 OMOP 2010 챌린지 우승 전략
초록
본 논문은 OMOP 2010 Cup Challenge 2에서 상위 성적을 거둔 방법을 소개한다. 1천만 환자 규모의 시뮬레이션 데이터베이스를 대상으로, 관측된 약물‑조건 패턴과 기대 패턴을 비교하는 비지도 학습 프레임워크를 구축하였다. 핵심 혁신은 랜덤 재표집( bagging )을 이용한 동질 앙상블을 적용해 다수의 베이스 학습기를 생성하고, 이를 평균화·가중합하여 최종 점수를 산출한 것이다. 시간 구간을 연도별로 나누어 단계적 평가를 수행하고, 약물 사용 기간( drug eras )을 고려한 두 가지 기대값 모델을 결합함으로써 MAP(Mean Average Precision) 점수를 0.12‑0.14 수준에서 0.21‑0.23 수준으로 크게 향상시켰다.
상세 분석
이 연구는 대규모 관찰 코호트 데이터에서 약물과 의료조건 사이의 잠재적 연관성을 탐지하기 위해 비지도 학습 접근법을 설계하였다. 데이터는 10년 관찰 기간 동안 1천만 명의 환자를 포함하고, 각 환자는 약물 복용 시작·종료일과 질환 발생일을 기록한다. 전체 가능한 약물‑조건 조합은 5,000 × 4,519 ≈ 2.26 × 10⁷ 개이며, 라벨이 제공된 소규모 검증 집합(4,000 + 3,920)만을 학습에 활용하지 않았다.
첫 단계에서는 “Disproportionality Analysis(DPA)”를 적용해 약물 복용 시점 이후 Δ(30–60일) 내에 질환이 발생한 경우의 관측 횟수 d_cn을 계산하고, 약물과 질환 각각의 전체 발생 빈도(d_n, c_n)를 이용해 기대 횟수 λ를 추정한다. λ는 독립 가정 하에 d_n·c_n·Δ / N 형태로 정의되며, 여기서 N은 전체 환자 수이다. 이후 관측/기대 비율을 로그 또는 거듭제곱 변환 f와 평활 파라미터 α(0.5–1.0)로 조정해 점수 α_dc를 산출한다.
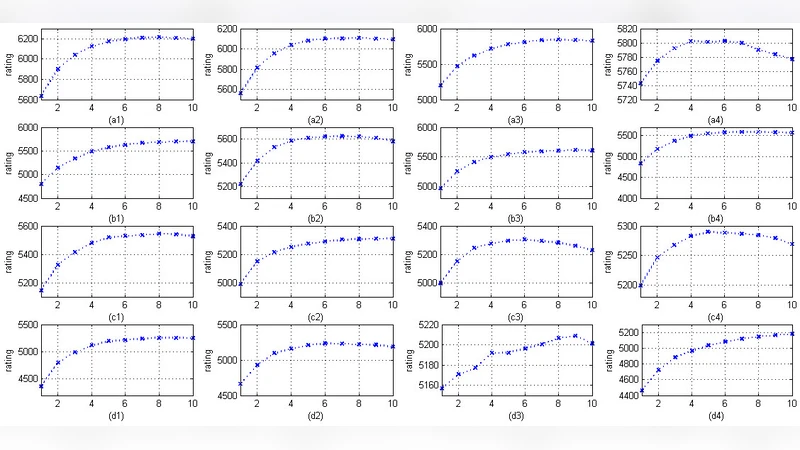
시간적 세분화를 위해 전체 10년을 m=10개의 연도 구간으로 나누고, 각 구간별 α_dc를 재계산한다. 이렇게 하면 데이터가 누적될수록 점수가 어떻게 변하는지를 추적할 수 있어 Challenge 2의 “시간 누적 평가” 요구에 부합한다.
핵심 혁신은 동일한 DPA 모델을 여러 번 랜덤 서브샘플( k=100, γ∈U
댓글 및 학술 토론
Loading comments...
의견 남기기