추상 모델 검증에서 허위 반례를 빠르게 탐지하는 방법
초록
본 논문은 추상화‑정제 루프에서 발생하는 허위(counterexample) 반례를 형식적으로 정의하고, 이를 효율적으로 식별하기 위한 새로운 알고리즘들을 제안한다. 기존 SplitPath 방법이 전체 경로의 접두사에 의존해 반복적인 루프 전개가 필요했던 문제를, 전·후 상태만을 이용해 실패 상태를 판별함으로써 해결한다. 또한 가장 “무거운”(다수 경로에 공통으로 등장하는) 실패 상태를 우선적으로 정제하는 전략과, 병렬 처리에 적합한 알고리즘 설계를 제시한다.
상세 분석
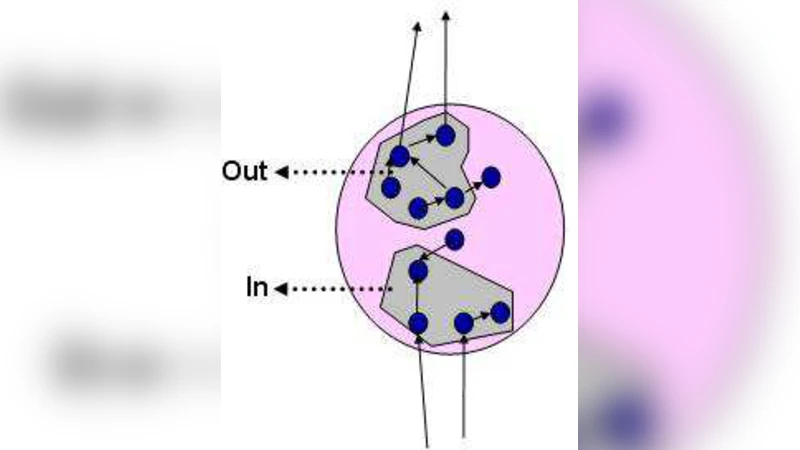
이 논문은 추상 모델 검증에서 가장 핵심적인 병목인 허위 반례 판별 문제를 깊이 파고든다. 먼저 저자들은 추상 함수 h: S → Ŝ를 통해 구체 상태 집합 S를 추상 상태 집합 Ŝ로 매핑하고, 각 추상 상태 ŝ에 대해 원본 상태들의 역이미지 h⁻¹(ŝ)를 정의한다. 허위 반례는 “실패 상태”(failure state)라는 개념으로 정형화된다. 실패 상태 ŝᵢ는 두 집합 In̂(ŝᵢ)와 Out̂(ŝᵢ)의 교집합이 공집합일 때 발생한다. 여기서 In̂(ŝᵢ)는 이전 추상 상태 ŝᵢ₋₁에서 들어오는 경로를 통해 도달 가능한 원본 상태들의 집합이며, Out̂(ŝᵢ)는 다음 추상 상태 ŝᵢ₊₁로 나가는 경로를 통해 도달 가능한 원본 상태들의 집합이다. 즉, In̂(ŝᵢ)∩Out̂(ŝᵢ)=∅이면 해당 추상 상태는 구체 모델에서 전·후 연결이 전혀 존재하지 않으므로, 그 상태를 포함하는 반례는 실제로는 존재하지 않는다.
기존의 SplitPath 알고리즘은 각 ŝᵢ에 대해 전체 접두 ŝ₀…ŝᵢ₋₁을 재귀적으로 탐색해야 하므로, 무한 루프가 포함된 반례에서는 루프를 다항식 횟수만큼 전개해야 하는 비효율성이 있었다. 논문은 이를 개선하여, In̂와 Out̂를 직접 계산함으로써 ŝᵢ 자체와 바로 전·후 상태만을 사용해 실패 여부를 판단한다. 이 접근법은 “Complete Finite Prefix”(CFP)만을 검사하면 충분하므로, 무한 반례에서도 루프 전개의 필요성을 크게 줄인다.
또한 저자들은 여러 실패 상태가 동시에 존재할 수 있음을 인식하고, 정제 비용을 최소화하기 위한 “가장 무거운” 실패 상태 탐지 전략을 제시한다. 여기서 무게는 E_in(ŝ)·E_out(ŝ) 으로 정의되며, 이는 해당 추상 상태에 진입·이탈하는 에지 수의 곱이다. 많은 경로가 공유하는 실패 상태를 먼저 정제하면 전체 추상‑정제 루프에서 모델 검사 횟수를 크게 감소시킬 수 있다.
마지막으로, 실패 상태 판별이 전·후 상태만을 필요로 한다는 점을 이용해 병렬 알고리즘을 설계한다. CheckSpurious‑III와 IV는 각 프로세서가 독립적으로 ŝᵢ 를 검사하고, 어느 하나가 실패 상태를 발견하면 즉시 전체 작업을 중단한다. 이는 현대 멀티코어·클러스터 환경에서 실시간으로 대규모 반례를 처리하는 데 큰 장점을 제공한다. 전체적으로 논문은 형식적 정의와 알고리즘 설계가 긴밀히 연결된 사례 연구를 통해, 기존 방법 대비 시간·공간 복잡도에서 실질적인 개선을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기