ParalleX 실행 모델과 HPX 런타임을 이용한 적응형 메쉬 정밀화 애플리케이션 확장성 연구
초록
본 논문은 차세대 Exascale 컴퓨팅을 목표로 기존 MPI 기반 CSP 모델의 한계를 지적하고, 메시지‑드리븐 흐름 제어와 경량 동기화 객체를 핵심으로 하는 ParalleX 실행 모델을 소개한다. ParalleX를 구현한 HPX 런타임을 이용해 적응형 메쉬 정밀화(AMR) 기반 수치 상대성론 시뮬레이션을 포팅하고, MPI 구현과 비교하여 확장성, 오버헤드, 그리고 하드웨어 가속 가능성을 평가한다.
상세 분석
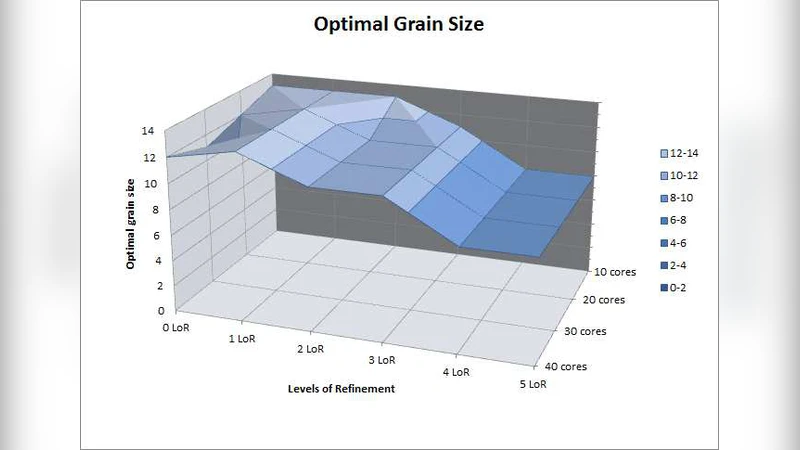
ParalleX 모델은 전통적인 CSP(Communicating Sequential Processes) 패러다임이 갖는 전역 장벽, 정적 데이터 분배, 그리고 높은 레이턴시 문제를 근본적으로 해결하고자 설계되었다. 핵심 개념은 (1) 활성 전역 주소 공간(Active Global Address Space, AGAS)으로, 모든 객체가 위치에 독립적인 전역 식별자를 갖게 함으로써 동적 로드 밸런싱과 데이터 이동을 투명하게 만든다. (2) 파셀(parcel) 메커니즘은 원격 함수 호출을 메시지 형태로 캡슐화하여, 작업을 데이터에 가까운 위치로 이동시키는 ‘move‑the‑work’ 전략을 구현한다. 파셀은 split‑phase 트랜잭션을 지원하므로, 호출자는 결과를 즉시 반환받지 않고, 필요 시 future 객체를 통해 비동기적으로 값을 조회한다. (3) 로컬 제어 객체(Local Control Objects, LCO)군은 future, dataflow, mutex, semaphore 등 경량 동기화 프리미티브를 제공한다. 특히 dataflow LCO는 선행 조건이 충족될 때 자동으로 후속 작업을 스케줄링함으로써 전역 장벽을 제거하고, 연산과 통신을 겹쳐 레이턴시를 숨긴다. (4) 미세 입자 수준의 HPX‑thread는 사용자 모드에서 비선점적으로 스케줄링되며, OS 스레드당 하나의 고정 스레드 풀을 사용해 컨텍스트 전환 비용을 최소화한다. 스레드 이동 대신 파셀을 통한 연속성(continuation) 전파를 선택함으로써, 원격 스레드 이동에 수반되는 스택·레지스터 복제 비용을 회피한다. HPX 구현은 이러한 개념을 C++ 표준과 Boost 라이브러리를 기반으로 모듈화했으며, 컴포넌트 프레임워크를 통해 애플리케이션 특화 모듈을 동적으로 로드한다. 성능 카운터와 퍼포먼스 모니터링 기능이 내장돼 실행 시점에 부하와 통신 패턴을 실시간으로 측정한다. 논문에서는 AMR 기반 수치 상대성론 코드에 HPX를 적용한 결과, 동일 문제 규모에서 MPI 버전에 비해 2배 이상 높은 효율을 달성했으며, 특히 높은 코어 수(수백에서 수천 코어)에서 확장성이 크게 개선됨을 보여준다. 오버헤드 분석에서는 파셀 전송 비용, LCO 관리 비용, 그리고 스레드 스케줄링 비용이 주요 요인으로 작용했으며, 이를 하드웨어 가속(예: FPGA 기반 파셀 엔진, NIC offload)으로 감소시킬 수 있음을 제시한다. 전체적으로 ParalleX는 ‘스타벅스 커피’처럼 작은 작업을 대량으로 섞어 실행함으로써, 전통적인 MPI가 겪는 ‘병목‑스레드’ 현상을 완화하고, Exascale 수준의 억대 코어 활용을 위한 소프트웨어 기반 토대를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기