비지도 K 최근접 이웃 회귀
초록
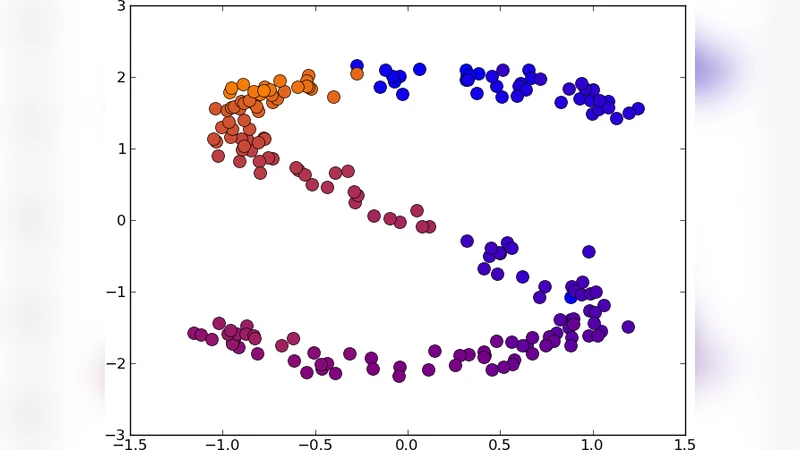
본 논문은 고차원 데이터의 비지도 차원 축소를 위해 K‑최근접 이웃(KNN) 회귀를 활용한 새로운 프레임워크인 UNN(Unsupervised Nearest Neighbor) 회귀를 제안한다. 저자는 고정된 1차원 잠재 공간 토폴로지를 가정하고, 두 가지 탐욕적 삽입 전략(UNN‑1, UNN‑2)을 통해 잠재 좌표를 순차적으로 배치한다. 실험에서는 2‑D·3‑D S곡선, 구멍이 있는 S곡선, USPS 손글씨 데이터 등에 적용해 데이터 공간 재구성 오차(DSRE)를 크게 감소시켰으며, UNN‑1이 정확도면에서 우수하고 UNN‑2가 실행 속도면에서 유리함을 확인하였다.
상세 분석
UNN 회귀는 기존의 비지도 회귀 프레임워크를 K‑NN 회귀에 적용함으로써, 잠재 변수 X가 고차원 관측 Y를 최소한의 재구성 오차(E(X)=‖Y‑f_UNN(X)‖F²)로 복원하도록 설계한다. 여기서 f_UNN(x;X)= (1/K)∑{i∈N_K(x,X)} y_i 로 정의되며, K‑nearest neighbor 집합 N_K는 잠재 공간 상의 거리 기준으로 결정된다. 중요한 점은 UNN이 절대 좌표보다는 이웃 관계에 초점을 맞추어, 잠재 공간 토폴로지를 고정(예: 등간격 1차원 격자)하고 순열 형태의 조합 탐색을 수행한다는 것이다.
첫 번째 전략 UNN‑1은 현재까지 삽입된 N̂ 개의 잠재 점 사이의 모든 N̂+1 가능한 삽입 위치를 평가한다. 각 위치에 대해 DSRE를 계산하고 최소값을 선택한다. 이 과정은 K·d 연산을 필요로 하며, 전체 복잡도는 O(N·K·d)≈O(N)이다. 두 번째 전략 UNN‑2는 새 데이터 y를 삽입할 때, 이미 삽입된 점 중 가장 가까운 y*를 찾고 그 양쪽 두 위치만 평가한다. 따라서 거리 계산에 N·d 연산이 추가되지만, 평가 횟수가 2로 제한돼 실제 실행 시간은 UNN‑1보다 약 10배 가량 빠르다.
실험에서는 K값을 2,5,10으로 변동시키며 DSRE를 비교하였다. 초기 DSRE는 수백에서 수천 수준이었으나, UNN‑1은 2‑D S곡선에서 K=2일 때 19.6으로, LLE(25.5)보다 크게 개선했다. UNN‑2도 대부분 경우에서 LLE보다 낮은 DSRE를 기록했지만, 정확도에서는 UNN‑1에 약간 뒤처졌다. 특히 K를 크게 할수록 DSRE가 상승하는 경향을 보였으며, 이는 K가 클수록 평균화 효과가 강해 세부 구조를 흐리게 하기 때문이다.
또한, USPS 손글씨 실험에서 1‑차원 잠재 공간에 2와 5를 각각 100개씩 배치했을 때, 인접한 잠재 점들 사이에 시각적으로 유사한 숫자가 군집되는 현상이 관찰되었다. 이는 UNN이 데이터의 내재적 순서를 보존하면서도 고차원 특징을 저차원에 효과적으로 투영한다는 증거다.
한계점으로는 현재 구현이 1‑차원 격자에 국한되어 있어 복잡한 토폴로지를 표현하기 어렵고, 탐욕적 삽입 방식이 전역 최적해를 보장하지 못한다는 점이다. 저자는 향후 2‑차원 이상의 격자 삽입, 전역 탐색을 위한 메타휴리스틱, 그리고 정규화 항을 통한 잠재 공간 확장 방지를 연구할 계획이라고 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기