복잡 게임 학습에서 나타나는 고차원 혼돈과 제한 주기
초록
플레이어가 경험 기반 강화학습(EWA)을 이용해 전략을 업데이트할 때, 가능한 행동 수가 많고 보상이 무작위인 ‘복잡 게임’에서는 파라미터 α(기억 손실)와 β(선택 강도), 그리고 제로섬 정도 Γ에 따라 고정점, 제한 주기, 혹은 고차원 혼돈 궤도로 수렴한다. 특히 비제로섬·긴 기억 상황에서 차원 수백에 달하는 혼돈 끌개가 나타나며, 보상은 간헐적 폭발‑정체 패턴을 보인다. 이는 전통적 균형 개념보다 동역학 시스템 이론이 더 적합함을 시사한다.
상세 분석
본 논문은 두 명의 플레이어가 N = 50개의 가능한 행동을 갖는 무작위 보상 행렬을 통해 반복 게임을 진행하고, 경험 가중치 매력(EWA) 학습 규칙을 적용하는 모델을 분석한다. 전략 확률 xᵤᵢ(t)는 매력 Qᵤᵢ(t)의 소프트맥스 형태로 정의되며, 매력은 α와 β에 의해 조정되는 기억‑감쇠와 선택 강도에 따라 업데이트된다. 보상 행렬 Πᵤ는 평균 0, 분산 1/N, 그리고 두 플레이어 간 상관계수 Γ/N을 갖도록 정규분포에서 샘플링한다. Γ = −1이면 완전 제로섬, Γ = 0이면 완전 비상관이다.
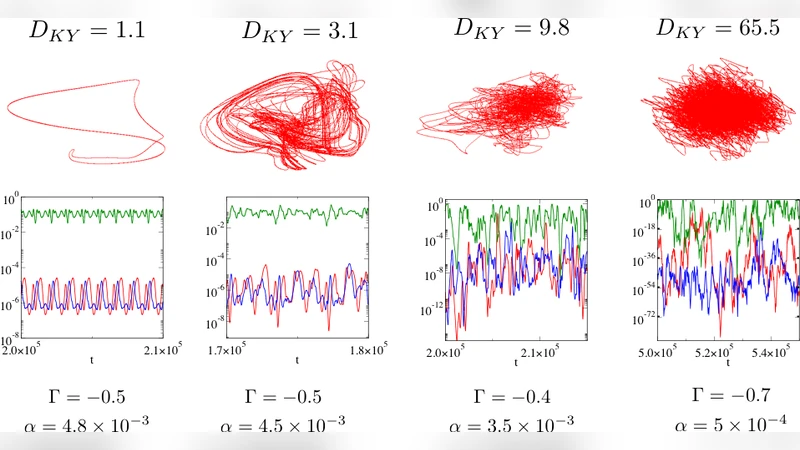
시뮬레이션 결과는 파라미터 공간을 크게 세 구역으로 구분한다. (1) Γ≈−1, α가 크고(짧은 기억) β가 작을 때, 모든 초기 조건이 고정점으로 수렴한다. 이는 기존 게임 이론의 내쉬 균형과 일맥상통한다. (2) Γ≈0, α가 작고(긴 기억) β가 중간 정도일 때, 전략 궤적은 제한 주기(limit cycle)를 형성한다. 주기의 형태와 진폭은 무작위 보상 행렬에 따라 변하지만, 주기성 자체는 안정적이다. (3) Γ가 −0.6 정도의 중간 반상관을 보이고 α가 매우 작으며 β가 충분히 큰 경우, Lyapunov 지수 중 양수가 다수 존재해 차원 D가 10~30에 달하는 고차원 혼돈 끌개가 나타난다. 이때 전략 확률 xᵤᵢ(t)는 급격한 폭발‑정체(intermittency)를 보이며, 보상 차이 ΔΠ(t) 역시 폭발적 변동과 긴 정체 구간을 반복한다. 이러한 현상은 유체 난류와 금융 시장의 클러스터드 변동성에 대한 통계적 유사성을 보여준다.
이론적 분석을 위해 저자들은 N→∞ 한계에서 경로 적분 방법을 적용해 안정 경계식을 도출하였다. 연속 시간 근사에서 안정성은 α/β 비율에만 의존한다는 결과가 나오며, 시뮬레이션에서 관측된 경계와 좋은 일치를 보인다. 또한 D가 N에 비례해 증가하는 경향을 확인했지만, 무한 N에서 D가 유한한 한계에 수렴하는지 혹은 무한히 커지는지는 아직 미정이다.
핵심 통찰은 다음과 같다. (i) 복잡 게임에서는 제로섬 정도와 기억 길이가 학습 동역학을 결정한다. (ii) 고차원 혼돈은 전략을 실질적으로 무작위화시켜, 어떤 학습 알고리즘도 충분한 데이터 없이 예측하거나 수렴시키기 어렵게 만든다. (iii) 전통적 균형 개념은 이러한 상황에 적용하기 부적절하며, 동역학 시스템 이론—특히 혼돈 이론과 통계 물리학—이 더 적합한 분석 틀을 제공한다. (iv) 금융 시장과 같은 실제 복잡 시스템에서 관측되는 간헐적 폭발·정체 현상은 게임 이론적 복잡성의 일반적 결과일 가능성이 높다.
댓글 및 학술 토론
Loading comments...
의견 남기기