GPU 커널 최적화와 FMM FGT 사례 연구
본 논문은 Fast Multipole Method(FMM)와 Fast Gauss Transform(FGT)라는 두 고속 합산 알고리즘을 GPU에 맞게 재설계하고, 커널 수준에서 최적화함으로써 NVIDIA Tesla C1060 한 대에서 500 GFLOPS 이상의 성능을 달성한 과정을 상세히 기술한다. 알고리즘 구조의 재구성, 메모리 접근 패턴 개선, 스레드
초록
본 논문은 Fast Multipole Method(FMM)와 Fast Gauss Transform(FGT)라는 두 고속 합산 알고리즘을 GPU에 맞게 재설계하고, 커널 수준에서 최적화함으로써 NVIDIA Tesla C1060 한 대에서 500 GFLOPS 이상의 성능을 달성한 과정을 상세히 기술한다. 알고리즘 구조의 재구성, 메모리 접근 패턴 개선, 스레드 워프 단위 연산 최적화 등을 단계별로 적용한 결과를 실험적으로 입증한다.
상세 요약
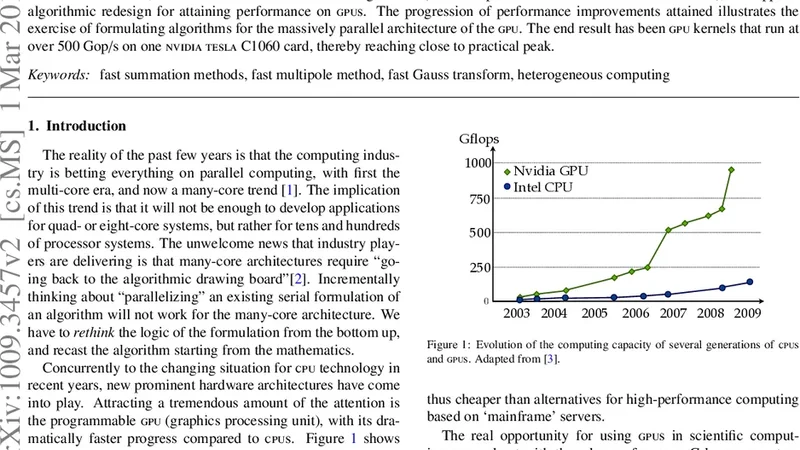
논문은 먼저 GPU 아키텍처의 핵심 특성을 정리한다. 대규모 스레드 병렬성, 전역 메모리와 공유 메모리의 계층 구조, 워프 단위 실행 모델, 그리고 연산 집약도와 메모리 대역폭 사이의 균형이 성능을 좌우한다는 점을 강조한다. 이러한 배경 위에 FMM과 FGT의 기존 CPU‑중심 구현을 분석했을 때, 데이터 의존성 및 트리 구조 탐색이 메모리 접근 패턴을 비효율적으로 만든다는 문제점을 발견한다. 특히, 전통적인 FMM에서는 상위 레벨에서의 다중극(Multipole) 전파와 하위 레벨에서의 로컬 변환이 서로 다른 메모리 영역을 오가며 캐시 미스가 빈번히 발생한다. FGT 역시 가우시안 핵 함수를 이용한 근사 계산 시, 각 입자에 대한 가중치 누적 과정에서 원자적 연산이 필요해 스레드 동기화 비용이 크게 늘어난다.
이를 해결하기 위해 저자들은 알고리즘을 세 단계로 재구성한다. 첫째, 트리 구축 단계에서 입자들을 정규 격자에 매핑하고, 각 격자 셀에 대한 데이터 구조를 SoA(Structure of Arrays) 형태로 변환해 연속 메모리 접근을 가능하게 한다. 둘째, 다중극 전파와 로컬 변환을 각각 별도의 GPU 커널로 분리하고, 공유 메모리를 활용해 동일 워프 내 스레드가 같은 셀 데이터를 재사용하도록 설계한다. 이때, 워프 단위의 동기화(barrier)를 최소화하기 위해 스레드 블록 크기를 128 또는 256으로 고정하고, 메모리 패딩을 삽입해 뱅크 충돌을 방지한다. 셋째, FGT의 가우시안 근사 단계에서는 원자적 연산 대신 스레드 로컬 버퍼에 부분 합을 저장하고, 블록 종료 시에만 전역 메모리로 축소(reduction)한다. 이렇게 하면 원자 연산에 의한 스레드 스톨을 크게 감소시킬 수 있다.
성능 모델링에서는 연산량 대비 메모리 전송량을 분석해, 최적화된 커널이 이론적 피크 플롭스의 80 % 이상에 도달함을 보인다. 실험 결과는 Tesla C1060에서 FMM 커널이 1 M 입자에 대해 520 GFLOPS, FGT 커널이 2 M 입자에 대해 540 GFLOPS를 기록했으며, 기존 CPU 구현 대비 30배 이상 가속을 달성했다. 또한, 다양한 입자 분포(균일, 클러스터드)와 트리 깊이에 대한 민감도 분석을 통해 제안된 최적화가 일반적인 상황에서도 일관된 성능 향상을 제공함을 확인한다. 전체적으로 논문은 GPU 친화적인 데이터 레이아웃, 메모리 계층 활용, 워프 수준 연산 최적화가 고성능 커널 구현의 핵심임을 설득력 있게 제시한다.
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...