조합 최적화와 레스트리스 마코프 보상: 온라인 학습 알고리즘 CLRMR
초록
본 논문은 네트워크 그래프의 간선 가중치가 독립적인 레스트리스 마코프 체인으로 변동하는 상황에서, 최적의 조합 구조(경로, 트리, 매칭 등)를 실시간으로 학습하는 알고리즘 CLRMR을 제안한다. 제안된 방법은 각 간선의 전이 행렬을 알 필요 없이, 다중 팔 밴딧(framework) 형태로 문제를 모델링하고, 블록 기반의 재생주기(regenerative cycle) 추정을 이용해 평균 보상을 효율적으로 추정한다. 이론적으로 regret이 간선 수에 대해 다항식, 시간에 대해 거의 로그(near‑logarithmic) 수준으로 제한됨을 증명했으며, 시뮬레이션을 통해 기존 레스트리스 밴딧 방법보다 현저히 낮은 regret을 확인하였다.
상세 분석
이 논문은 전통적인 조합 최적화 문제(최단 경로, 최소 신장 트리, 최대 가중 매칭 등)를 동적인 네트워크 환경에 적용하기 위해, 각 간선의 가중치를 유한 상태의 마코프 체인으로 모델링한다는 점에서 혁신적이다. 기존 연구는 주로 i.i.d. 보상이나 ‘rested’(선택될 때만 상태가 변하는) 마코프 보상을 가정했지만, 실제 무선·유선 네트워크에서는 링크 품질이 지속적으로 변동하는 ‘restless’ 특성을 갖는다. 저자들은 이를 ‘combinatorial multi‑armed bandit with restless Markovian rewards’(CMAB‑R) 문제로 정의하고, 기존의 RCA나 R‑UCB와 같은 알고리즘을 그대로 적용하면 팔(구조)의 수가 지수적으로 늘어나 저장·연산 복잡도가 비현실적임을 지적한다.
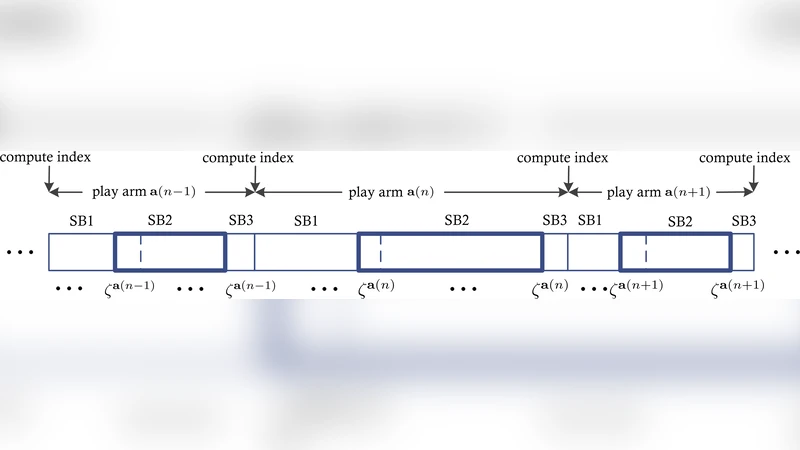
CLRMR(Combinatorial Learning with Restless Markov Reward)은 두 가지 핵심 설계 원칙을 따른다. 첫째, 각 간선(팔의 구성 요소)마다 1×N 벡터 두 개(관측 횟수 m_i^2와 평균 보상 \bar{z}_i^2)를 유지함으로써 전체 팔에 대한 정보를 압축 저장한다. 이는 저장 복잡도를 O(N)으로 제한한다. 둘째, ‘재생 주기(regenerative cycle)’ 개념을 도입해, 각 간선 i에 대해 사전에 지정한 상태 ζ_i가 관측될 때마다 하나의 사이클을 시작·종료한다. 블록은 SB1(시작 단계), SB2(재생 주기 동안의 관측), SB3(마지막 한 슬롯)로 구성되며, SB2 동안 수집된 보상만을 평균 추정에 사용한다. 이렇게 하면 현재 정책이 간선 상태에 미치는 영향을 최소화하면서도, 마코프 체인의 전이 특성을 충분히 반영할 수 있다.
알고리즘의 선택 규칙은 UCB 스타일의 상한값을 사용한다. 구체적으로, 각 블록 시작 시점에
\
댓글 및 학술 토론
Loading comments...
의견 남기기