다중 관계 그래프 클러스터링: 가중치 합성 및 메타‑클러스터링 탐구
초록
본 논문은 여러 종류의 유사도(엣지 타입)를 갖는 그래프에서 커뮤니티를 탐지하는 방법을 제시한다. 단일 가중치 그래프로 축소하는 대신, 각 엣지 타입에 가중치를 부여해 합성 가중치를 만들고, 이를 이용해 기존 클러스터링 알고리즘을 적용한다. 또한, 주어진 정답 클러스터링으로부터 최적 가중치 벡터를 역문제로 추정하고, 정답 클러스터링의 내부 정합성을 ‘보유력’(holding power) 개념으로 정량화한다. 메타‑클러스터링을 통해 다중 엣지 타입이 만들어내는 클러스터링 공간을 효율히 표현하고, 기존 클러스터링과 크게 다른 ‘예상치 못한’ 클러스터를 탐색하는 절차도 제안한다. 실험은 파일 시스템, Arxiv 논문, CIA World Factbook 데이터를 이용해 수행되었다.
상세 분석
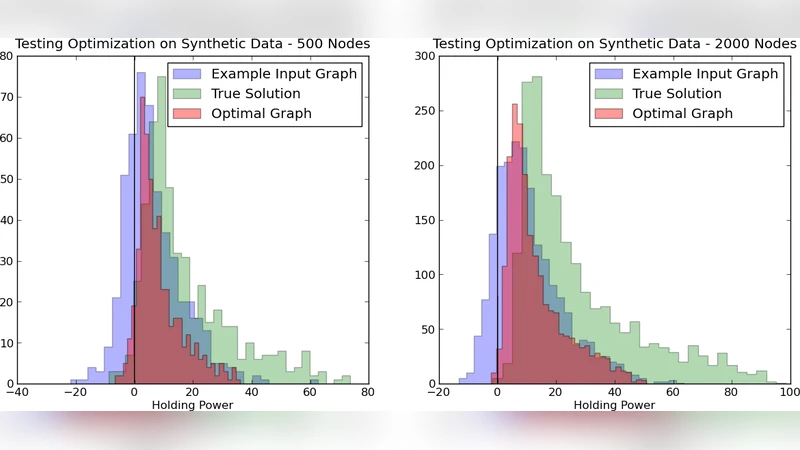
이 논문은 그래프 기반 커뮤니티 탐지 문제를 다중 엣지 타입(다중 유사도) 상황으로 일반화한다는 점에서 의미가 크다. 전통적인 단일 가중치 그래프는 여러 관계를 하나의 스칼라 값으로 압축하는데, 이 과정에서 중요한 구조적 정보를 손실할 위험이 있다. 저자들은 각 엣지 타입을 k‑차원 벡터 ~w_i 로 표현하고, 선형 결합 ω_i = ∑{j=1}^k α_j w{ij} 로 단일 가중치 그래프를 만든다. 여기서 핵심은 가중치 벡터 α를 어떻게 결정하느냐인데, 두 가지 접근법을 제시한다. 첫 번째는 ‘역문제(inverse problem)’ 방식으로, 임의의 α를 가정하고 기존 클러스터링 알고리즘(Graclus, FastCommunity 등)으로 얻은 클러스터링과 정답 클러스터링 사이의 변이 정보(variation of information, VI) 거리를 최소화한다. 이 방법은 전형적인 블랙‑박스 최적화 루프를 필요로 하며, 클러스터링 알고리즘 자체의 불완전성에 민감하다. 두 번째는 정답 클러스터링 자체의 품질을 직접 최적화한다. 이를 위해 저자들은 각 정점 v에 대해 ‘pull’ P_α(v, C_k)=∑{(u,v)∈E, u∈C_k} w{uv}(α) 를 정의하고, 해당 정점이 속한 클러스터와 두 번째로 큰 pull 사이의 차이를 ‘보유력’ H_α(v) 로 정의한다. 보유력이 양수이면 정점이 올바른 클러스터에 강하게 묶여 있음을 의미한다. 최적화 목표는 arctan(H_α(v))의 합을 최대화하는 것으로, arctan 함수는 단계적(0/1) 목표를 부드러운 형태로 근사해 미분 가능한 형태를 제공한다.
전체 클러스터링 품질을 동시에 고려하기 위해 저자들은 모듈러리티(modularity)를 사용한다. 모듈러리티는 무작위 그래프(동일한 차수 분포)와의 차이를 측정하므로, 가중치 합성 후에도 의미 있는 커뮤니티 구조를 유지한다. 선형 목표(예: cut edge weight 최소화)는 한 가지 엣지 타입에 모든 가중치를 몰아넣는 트리비얼 해를 초래하므로, 비선형 목표와 제약을 도입해 다중 정보를 균형 있게 활용한다.
알고리즘 구현 측면에서, 파생식이 없는 비선형 최적화 문제를 해결하기 위해 HOPSPACK이라는 파라렐 무파생식 최적화 패키지를 사용한다. 이는 대규모 그래프에서도 실용적인 탐색을 가능하게 한다.
논문은 또한 ‘메타‑클러스터링(meta‑clustering)’ 개념을 도입한다. 다중 엣지 타입이 생성하는 여러 클러스터링을 클러스터링 공간의 점으로 보고, 이들 사이의 VI 거리를 기반으로 또다시 클러스터링을 수행한다. 결과적으로 클러스터링 자체가 군집을 이루는 구조를 드러낼 수 있다. 이를 통해 ‘예상치 못한’ 클러스터링, 즉 기존 클러스터링과 크게 거리(vi) 가 큰 새로운 커뮤니티를 탐색한다.
실험에서는 (1) 파일 시스템 데이터를 이용해 파일‑프로젝트 관계를 복원, (2) Arxiv 논문을 저자·키워드·인용·제목 등 4가지 메트릭으로 구성한 다중 그래프에 적용, (3) CIA World Factbook 국가 데이터를 지리·경제·정치·문화 등 여러 속성으로 모델링한 사례를 제시한다. 각 사례에서 제안된 가중치 추정 및 메타‑클러스터링이 단일 메트릭 기반 방법보다 더 풍부하고 의미 있는 커뮤니티 구조를 발견함을 보인다.
전체적으로 이 연구는 다중 관계 그래프에서 클러스터링을 수행할 때, 가중치 합성, 정답 기반 파라미터 추정, 비선형 최적화, 메타‑클러스터링이라는 네 가지 핵심 기술을 통합함으로써 기존 방법의 한계를 극복하고, 실제 데이터에 적용 가능한 프레임워크를 제공한다는 점에서 큰 의의를 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기