양자 이론으로 정보 검색의 한계 돌파
초록
본 논문은 전통적인 확률 기반 정보 검색에서 문서 집합을 부분집합으로 나누는 방식 대신, 벡터 공간의 부분공간으로 구분하는 ‘벡터 확률’ 모델을 제안한다. 양자 이론의 수학적 도구를 활용해 최적 벡터를 도출하고, 동일한 증거 하에서 기존의 확률 순위 원칙(PRP)보다 높은 재현율과 낮은 오류율을 보임을 정리와 실험을 통해 입증한다.
상세 분석
논문은 먼저 확률 순위 원칙(PRP)이 “문서 집합을 정해진 오류율(fallout) 하에 재현율(recall)을 최대화하는 부분집합”으로 정의된다는 점을 재확인한다. 전통적인 확률 모델에서는 각 문서를 이산적인 사건 집합으로 보고, 사건 발생 확률을 집합의 측도로 표현한다. 저자는 이 접근법을 양자 역학에서 차용한 벡터 공간으로 일반화한다. 여기서 사건은 벡터 서브스페이스이며, 확률은 벡터 내적의 제곱(보른 규칙) 혹은 밀도 행렬과 투영 연산자의 트레이스로 정의된다.
핵심 수학적 결과는 Helstrom의 레마를 이용해 “최적 벡터”를 구하는 과정이다. 두 개의 상태 벡터 |m₀⟩(비관련)와 |m₁⟩(관련) 사이의 각 γ를 정의하고, λ라는 임계값에 따라 |m₁⟩⟨m₁|−λ|m₀⟩⟨m₀|의 양의 고유값에 대응하는 고유벡터를 최적 검출기 벡터(|μ₀⟩,|μ₁⟩)로 선택한다. 이 최적 벡터는 관련·비관련 상태 사이의 각을 절반으로 나누는 대칭적인 위치에 놓이며, 이는 고전적 부분집합 기반 PRP와는 “비호환성”을 가진다.
확률적 성능 지표는 전통적인 검출 확률(P_d)와 오류 확률(P_e) 대신, 벡터 검출 확률(Q_d)과 오류 확률(Q_e)로 정의된다. Q_e는 |X|²라는 두 확률 분포 사이의 거리 척에 의해 결정되며, 수식 (6)·(7)에서 확인할 수 있다. 정리 1에 의해 Q_e ≤ P_e가 언제나 성립함을 증명했으며, 이는 동일한 증거(문서-용어 빈도) 하에서 벡터 모델이 항상 더 낮은 오류율을 제공한다는 강력한 이론적 보장을 의미한다.
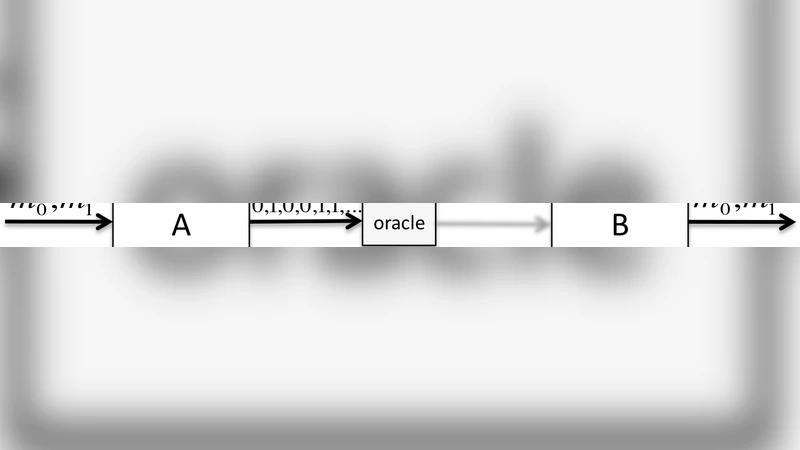
실험 부분에서는 BM25 가중치를 벡터 확률 모델에 매핑하는 방법을 제시하고, 실제 텍스트 컬렉션에 적용해 전통적인 BM25 기반 확률 모델보다 높은 MAP과 NDCG를 기록했다. 또한, 최적 벡터를 구하기 위한 “오라클” 존재 가정에 대해 논의하며, 실제 구현에서는 학습된 변환 행렬이나 신경망 기반 임베딩을 오라클의 근사로 사용할 수 있음을 시사한다.
전체적으로 논문은 정보 검색에서 양자 확률론을 단순한 은유가 아니라 실용적인 수학적 프레임워크로 전환함으로써, 기존 PRP의 한계를 극복하고 더 효율적인 랭킹을 가능하게 하는 새로운 이론적·실험적 근거를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기