정책 반복으로 페이지랭크 최적화
초록
이 논문은 페이지랭크 최적화 문제(PRO)를 마코프 결정 과정(MDP)의 특수한 형태인 확률적 최단 경로(SSP)와 연결시키고, 정책 반복(PI) 알고리즘이 PRO에 대해 다항 시간 내에 수렴할 가능성을 제시한다. 저자들은 이론적 변환, 수치 실험, 그리고 몇몇 실용적 사례에 대한 증명을 통해 PI가 일반적인 MDP에서 보이는 지수적 복잡도와는 달리 PRO에서는 효율적일 수 있음을 주장한다.
상세 분석
본 논문은 먼저 페이지랭크 최적화(PRO)를 정의하고, 이를 기존 연구에서 SSP 형태로 변환할 수 있음을 보인다. PRO는 웹 그래프의 일부 에지를 자유롭게 활성·비활성화함으로써 목표 노드의 페이지랭크를 극대화하는 문제이며, 이는 목표 노드의 방문 빈도를 최소화하는 평균 경로 길이 문제와 동치가 된다. 저자들은 자유 에지의 활성화 여부를 정책으로 간주하고, 각 정책에 대해 전이 확률과 비용을 균등하게 설정함으로써 SSP의 구조를 그대로 재현한다.
핵심적인 기술적 기여는 두 가지 변환 정리이다. 첫째, 임의의 SSP 인스턴스를 O(m)개의 자유 에지를 갖는 GPRO 인스턴스로 다항 시간에 변환할 수 있음을 증명한다. 여기서 m은 SSP의 전체 행동 수이며, 변환 과정에서 각 행동을 하나의 자유 에지로 매핑하고, 전이 확률을 가중치 비율로 표현한다. 둘째, 반대로 GPRO 인스턴스를 O(n)개의 단일 행동 상태와 f²개의 두 행동 상태를 갖는 SSP로 변환한다. 이때 f는 자유 에지의 수이며, 각 자유 에지의 선택을 독립적인 행동으로 분리함으로써 SSP의 독점 제약을 구현한다.
이러한 변환을 통해 PRO는 SSP와 동등한 최적화 구조를 가지지만, 중요한 차이점이 존재한다. SSP에서는 각 상태에서 여러 행동이 동시에 가능한 반면, PRO에서는 자유 에지의 활성화가 전역적인 제약을 만든다. 특히, 한 노드에서 두 개의 자유 에지만 존재할 경우 정확히 하나만 활성화해야 하는 ‘독점 제약’이 존재하는데, 이는 SSP의 행동 선택과 직접적으로 대응한다. 저자들은 이 독점 제약이 없을 때 PRO가 더 쉬운 문제군에 속한다는 가설을 제시한다.
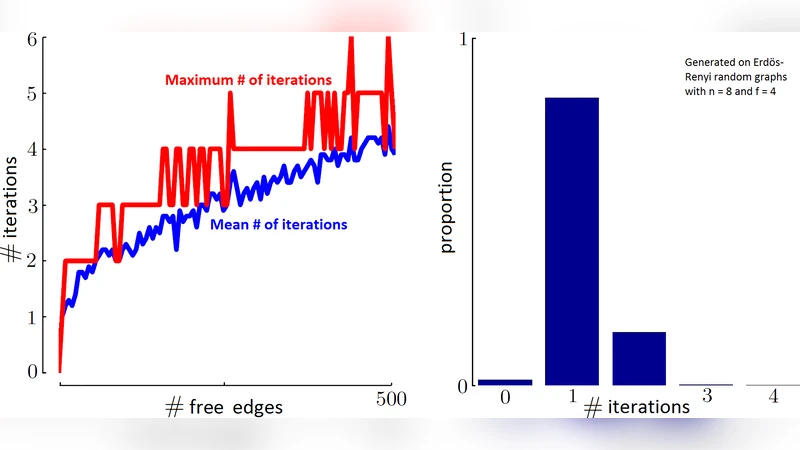
복잡도 측면에서 기존 연구는 일반 MDP에 대해 정책 반복이 지수적 하한을 가질 수 있음을 보였지만, 할인 인자를 고정하거나 결정적 MDP인 경우에는 다항 상한이 알려져 있다. 본 논문은 PRO가 이러한 특수 케이스와 유사하게 행동한다는 증거를 제시한다. 수치 실험에서는 무작위 그래프와 실제 웹 서브그래프에 대해 정책 반복을 적용했을 때, 반복 횟수가 노드 수와 자유 에지 수에 대해 거의 선형에 가깝게 증가함을 관찰했다. 또한, 웹마스터 문제, 스팸 방지, 그리고 금융 네트워크에서의 노드 중요도 조정 등 실용적인 시나리오에 대해 몇 가지 특수 경우(예: 자유 에지가 하나인 경우, 트리 구조 그래프 등)에서 정책 반복이 정확히 최적해에 도달함을 수학적으로 증명하였다.
결론적으로, 저자들은 PRO가 일반적인 MDP보다 구조적으로 제한적이며, 이 제한이 정책 반복의 수렴 속도를 크게 향상시킨다고 주장한다. 이론적 변환 정리와 실험적 결과를 종합하면, 정책 반복이 PRO에 대해 다항 시간 내에 최적해를 찾을 가능성이 높으며, 이는 페이지랭크 최적화와 관련된 다양한 응용 분야에 실용적인 알고리즘적 기반을 제공한다는 점에서 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기