기업 경쟁 네트워크의 자기 조직화 구조
초록
본 논문은 미국 내 기업 본사의 위치와 경쟁 관계를 기반으로 한 대규모 유향 네트워크를 구축하고, 그 구조적·공간적 특성을 분석한다. 기업 간 경쟁은 비대칭적이며, 대부분의 기업은 소수의 경쟁자를 인식하지만 일부 대기업은 다수에게 경쟁자로 인식된다. 기업 본사 밀도는 인구 밀도와 강하게 연관되고, 두 기업이 경쟁 관계가 될 확률은 거리 증가에 따라 급감한다. 이러한 경험적 규칙을 반영한 두 가지 미시적 성장 모델을 제시해 실제 네트워크의 차수 분포와 거리 의존성을 성공적으로 재현한다.
상세 분석
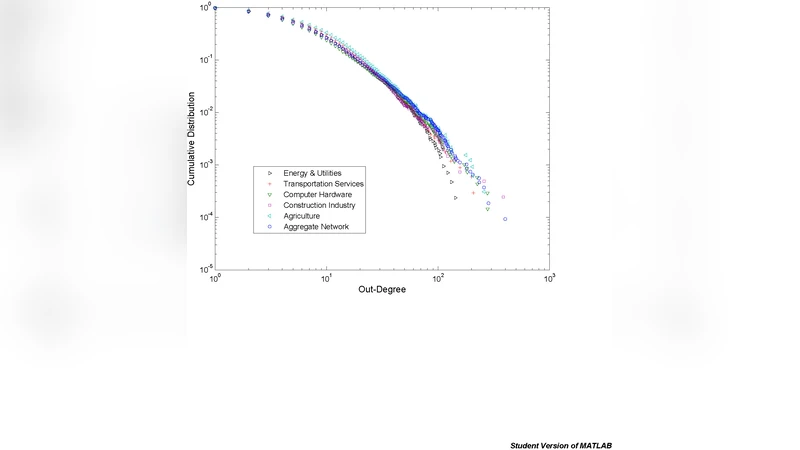
논문은 먼저 Hoover 데이터베이스를 활용해 미국 본사만을 대상으로 10,753개의 기업과 94,953개의 경쟁 링크를 수집하였다. 네트워크는 유향이며 평균 차수는 약 9이고, 전체 링크의 40%가 상호 경쟁(양방향) 형태를 보인다. 차수 분포는 전형적인 스케일프리 형태를 띠며, 특히 out‑degree와 in‑degree가 서로 다른 꼬리 길이를 보여 비대칭성을 드러낸다. 이는 기업이 스스로 인식하는 경쟁자 수와 다른 기업이 자신을 경쟁자로 인식하는 수가 다름을 의미한다.
공간적 분석에서는 기업 본사 위치가 인구 밀도와 거의 선형적으로 상관함을 확인했으며, 두 기업 사이의 경쟁 확률은 거리 d에 대해 P(d)∝e^{‑αd} 혹은 d^{‑β} 형태의 급격한 감소를 보였다. 이는 ‘중력 모델’과 유사하지만, 경제 규모 대신 인구와 거리만을 변수로 사용한다는 점에서 차별화된다.
모델링 부분에서는 두 가지 미시적 성장 메커니즘을 제안한다. 첫 번째 모델은 새로운 기업이 무작위 위치에 등장하되, 기존 기업의 인구밀도와 거리 가중치를 곱한 확률로 연결되는 방식이다. 두 번째 모델은 기존 기업의 차수를 기반으로 하는 누적우위(cumulative advantage) 원리를 도입하면서, 거리 감쇠 함수를 추가한다. 두 모델 모두 파라미터 튜닝을 통해 실험적 차수 분포와 거리‑연결 함수와의 일치를 확인했으며, 특히 큰 차수의 ‘허브’ 기업이 소수 존재하고, 대부분의 기업은 낮은 차수를 갖는 구조를 재현한다.
이러한 결과는 기업 경쟁 네트워크가 물리적 거리와 인구 분포라는 외부 제약 하에서 자체 조직화(self‑organization) 과정을 겪으며, 복잡계 이론의 일반적 메커니즘—우선 연결성, 거리 감쇠, 누적우위—이 경제 사회 시스템에도 적용될 수 있음을 시사한다. 또한, 비대칭적 경쟁 인식은 정책 입안 시 특정 기업을 목표로 하는 규제나 지원이 네트워크 전체에 미치는 파급 효과를 재평가할 필요성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기