양자 집합 모델로 보는 언어 빈도 분석
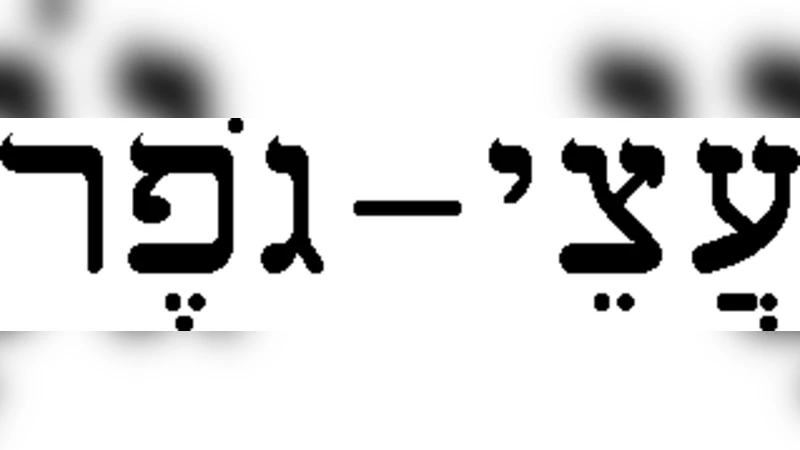
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 텍스트 내 단어 빈도 분포를 양자 통계 물리의 보스-아인슈타인 분포와 유사하게 모델링한다. “온도”라는 새로운 매개변수를 도입해 언어별 특성을 정량화하고, 영어·우크라이나어·기니 마닌카어의 코퍼스를 분석한다. 실험 결과, 언어의 분석성(analyticity) 수준과 제시된 온도·화학퍼텐셜 파라미터 사이에 의미 있는 상관관계가 존재함을 확인하였다.
상세 분석
이 연구는 언어학적 현상을 물리학의 양자 집합 모델에 매핑함으로써 전통적인 통계적 방법을 넘어서는 새로운 정량적 도구를 제시한다. 먼저 저자들은 단어 빈도 데이터를 Zipf 법칙과 같은 기존 모델과 비교했을 때, 고빈도 단어와 저빈도 단어 사이의 비선형적 관계가 보스-아인슈타인(BE) 분포의 형태와 유사함을 발견한다. BE 분포는 입자들이 동일한 양자 상태에 다수 집합될 수 있는 특성을 갖는데, 이는 텍스트에서 흔히 나타나는 “핵심 어휘”가 반복적으로 사용되는 현상과 일맥상통한다.
이를 수학적으로 표현하기 위해 저자들은 단어 종류를 ‘에너지 레벨’, 단어 등장 횟수를 ‘입자 수’에 대응시켰으며, 다음과 같은 BE 형태의 확률 밀도 함수를 도입한다:
\
댓글 및 학술 토론
Loading comments...
의견 남기기