우간다 표형 데이터에 대한 프라이버시 보호 기술 적용
초록
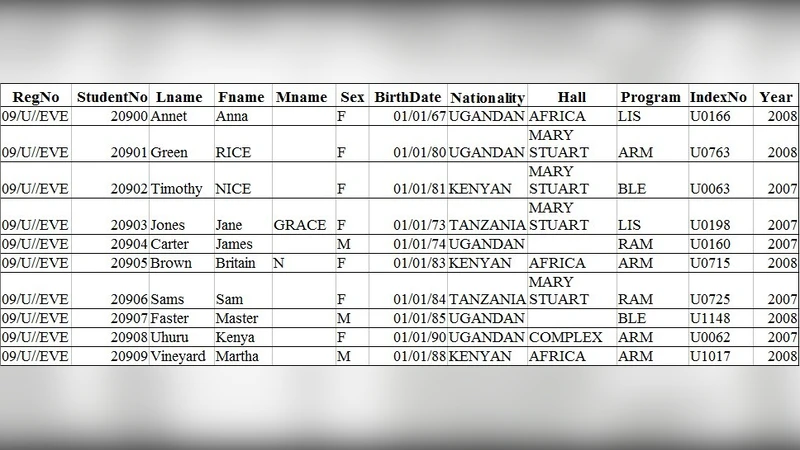
본 논문은 우간다에서 공개되는 표형(탭형) 데이터에 대한 개인정보 보호 필요성을 강조하고, 현행 법·제도적 공백을 지적한다. 저자는 미국의 개인정보 정의를 기준으로 PII를 식별한 뒤, k‑anonymity, 억제(suppression), 일반화(generalization) 기법을 결합해 Makerere University 입학 기록 1,200건을 익명화하는 실험을 수행한다. 구현 절차와 데이터 유틸리티 평가를 제시하며, 우간다·아프리카 전역에서 저비용·저복잡도 방식으로 데이터 프라이버시를 구현할 수 있음을 주장한다.
상세 분석
이 논문은 우간다의 급격한 ICT 성장과 동시에 데이터 프라이버시 보호 체계가 미비함을 지적한다. 우간다 헌법은 ‘사생활 침해 금지’를 명시하지만, 구체적인 PII 정의나 전자 데이터 보호 규정은 부재하다. 저자는 이러한 제도적 공백을 보완하기 위해 기존 국제법(미국 HIPAA 등)의 PII 개념을 임시 기준으로 채택하고, 기술적 차원에서 비침해적·침해적 기법을 구분한다. 특히, 비침해적 방법인 억제와 일반화, 그리고 k‑anonymity를 결합한 절차를 제시한다. 실험에서는 Makerere University의 입학 명단을 대상으로, 식별자(이름, 학번 등)를 제거하고, 성별·출생연도·국적을 quasi‑identifier로 설정한 뒤, k>1을 만족하도록 일반화·억제를 반복 적용한다. 이 과정에서 데이터 유틸리티(통계적 의미 보존)를 검증하기 위해 원본과 변형 데이터의 분포 차이를 확인한다. 논문은 k‑anonymity 구현이 NP‑hard 문제임을 인정하면서도, 소규모 조직이나 학술기관이 손쉽게 적용 가능한 워크플로우를 제시한다는 점에서 실용적이다. 그러나 민감 속성(sensitive attribute)이 전혀 없다고 가정하고, l‑diversity·differential privacy와 같은 고급 기법을 배제한 점은 제한점으로 남는다. 또한, 미국식 PII 정의를 그대로 적용함으로써 현지 문화·사회적 특성(예: 주민등록번호 부재)과의 불일치가 발생할 가능성이 있다. 향후 연구에서는 현지 법제화와 함께, quasi‑identifier 선정 기준을 현지 데이터 특성에 맞게 재정립하고, l‑diversity·t‑closeness·differential privacy를 통합한 하이브리드 모델을 탐색해야 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기