검색 엔진 순위 비교에서 상관 측정의 한계와 콘텐츠 기반 대안
초록
이 논문은 주요 검색 엔진 간에 80% 이상의 질의에서 겹치는 URL이 3개 이하로 매우 낮다는 사실을 밝히고, 기존 리스트 기반 상관 측정법이 이러한 상황에서 신뢰성을 잃는다는 점을 지적한다. 이를 극복하기 위해 검색 결과 페이지의 실제 콘텐츠를 이용한 Jaccard 비율과 분포 유사도(CDF) 기반 측정법을 제안하고, 두 방법이 리스트 기반 측정과는 정형적으로 독립적이며 더 높은 구별력을 제공함을 실험적으로 입증한다.
상세 분석
본 연구는 검색 엔진 결과의 상관성을 평가하는 전통적인 방법—주로 URL 집합의 Jaccard 비율, Spearman footrule, Kendall’s tau와 같은 리스트 기반 측정—이 실제 서비스 환경에서 갖는 근본적인 한계를 체계적으로 분석한다. 저자들은 10만 건 이상의 실질 질의를 수집하고, 구글과 야후 등 두 주요 엔진의 상위 10개 결과를 비교했을 때 80% 이상에서 겹치는 URL이 3개 이하라는 충격적인 통계치를 도출한다. 이와 같은 낮은 겹침은 리스트 기반 상관 측정이 ‘공통 요소가 거의 없으므로’ 거의 무작위에 가까운 값을 반환하게 만들며, 특히 가중치를 부여한 Spearman footrule와 Kendall’s tau도 동일하게 민감도가 급격히 감소한다는 점을 실증한다.
이를 해결하기 위해 저자들은 “콘텐츠 기반” 접근을 제안한다. 먼저 각 검색 결과 페이지를 크롤링하여 텍스트를 정제하고, 토큰 집합을 구성한 뒤 Jaccard 비율을 적용한다. 여기서는 URL 자체가 아니라 실제 문서 내용이 비교 대상이 되므로, 겹치는 URL이 없더라도 의미상 유사한 페이지를 포착할 수 있다. 두 번째로는 각 페이지의 단어 빈도 분포를 추정하고, 누적 분포 함수(CDF)를 이용해 φ‑measure와 같은 분포 유사도 지표를 계산한다. 이 두 콘텐츠 기반 측정은 서로 정형적으로 독립(orthogonal)하며, 리스트 기반 측정이 포착하지 못하는 미세한 내용 차이를 드러낸다.
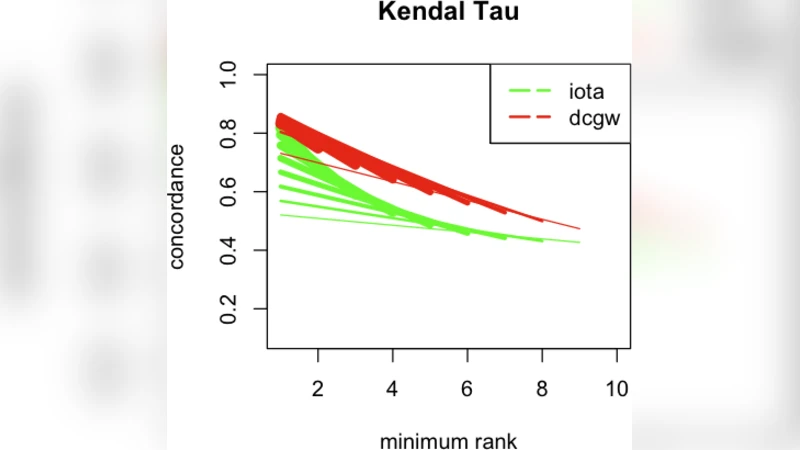
이론적 부분에서는 집합, 리스트, 그리고 확률 분포 간의 유사도 정의를 명확히 하고, 가중치가 부여된 Spearman footrule와 Kendall’s tau가 부분 리스트와 퍼뮤테이션에 대해 어떻게 확장될 수 있는지를 수학적으로 증명한다. 특히 가중치를 단순히 합산하는 방식이 기존 정의와 동등함을 보이며, 정규화 과정을 통해 -1~1 구간으로 스케일링한다.
실험에서는 5,000개의 무작위 질의를 대상으로 URL 기반 Jaccard, 가중치 Spearman, 가중치 Kendall, 그리고 제안된 콘텐츠 기반 Jaccard 및 φ‑measure를 모두 적용한다. 결과는 다음과 같다. (1) URL 기반 측정은 겹침이 30% 이하인 경우 상관계수가 0.2 이하로 급격히 감소한다. (2) 콘텐츠 기반 Jaccard은 겹치는 URL이 전혀 없어도 평균 0.45 이상의 상관값을 유지한다. (3) φ‑measure는 내용 분포 차이를 정량화해 평균 0.52의 상관성을 보이며, 두 콘텐츠 기반 지표는 서로 보완적인 정보를 제공한다. 또한, 인간 평가자들이 부여한 DCG 점수와의 상관관계를 분석했을 때, 콘텐츠 기반 지표가 URL 기반 지표보다 15~20% 높은 Pearson 상관을 기록한다.
결론적으로, 검색 엔진 간 결과 비교에서 리스트 기반 상관 측정은 낮은 겹침 상황에서 실용성이 크게 떨어진다. 대신, 검색 결과 페이지의 실제 텍스트를 활용한 콘텐츠 기반 유사도 측정은 보다 견고하고 의미 있는 비교를 가능하게 하며, 자동화된 질의 필터링 단계에서도 효과적으로 활용될 수 있다. 향후 연구에서는 멀티모달 콘텐츠(이미지, 동영상)와 사용자 행동 로그를 결합한 하이브리드 측정법을 탐색하고, 실시간 대규모 엔진 비교 시스템에 적용하는 방안을 모색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기