멀티GPU 자동 코드 생성으로 전기기계 시뮬레이션 가속
초록
본 논문은 모델 기반 엔지니어링(MDE)과 MARTE 프로파일을 활용해 CPU‑GPU 하이브리드 시스템용 OpenCL 코드를 자동 생성하는 방법을 제시한다. 전기기계 시뮬레이션에 널리 사용되는 공액 Gradient(CG) 알고리즘을 사례로, 1·2·4 GPU 환경에서 자동 생성된 코드를 실험하여 순차 Matlab 구현 대비 최대 2.5배의 속도 향상을 확인하였다.
상세 분석
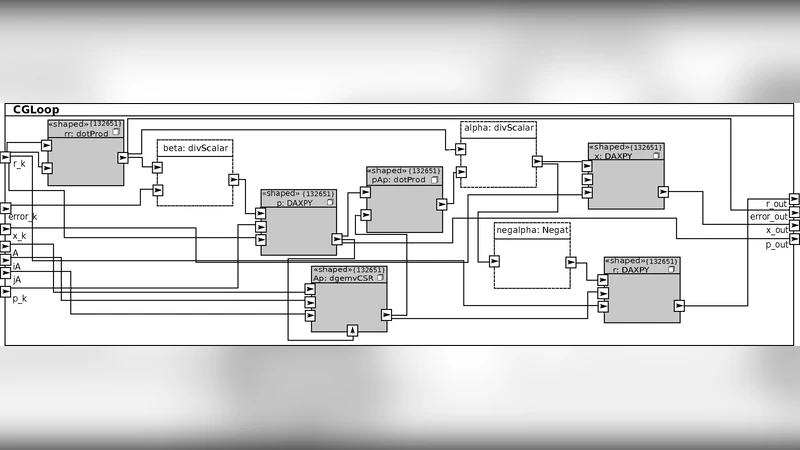
이 연구는 전기·전자 공학 분야에서 대규모 수치 해석을 수행할 때 필연적으로 요구되는 병렬 프로그래밍의 복잡성을 모델 기반 자동화로 해소하고자 한다. 핵심은 UML 기반 MARTE 프로파일을 이용해 알고리즘의 기능적 구조와 실행 플랫폼의 자원 특성을 동시에 기술하고, 이를 Gaspard2 프레임워크가 지원하는 모델‑투‑모델·모델‑투‑텍스트 변환 체인에 투입해 OpenCL 소스와 호스트 코드를 자동 생성한다는 점이다. MARTE의 ‘stereotype’와 ‘constraint’를 활용해 작업(task)과 데이터 흐름을 명시하고, 각 작업을 CPU와 GPU 중 어디에 배치할지 모델 단계에서 결정한다. 변환 과정에서 CSR 형식의 희소 행렬, DGEMV와 같은 BLAS‑유사 연산을 GPU 커널로 매핑하고, 반복적인 CG 루프는 다중 GPU에 균등 분할하도록 스케줄링한다.
자동 생성된 코드는 OpenCL 런타임이 제공하는 컨텍스트와 커맨드 큐를 활용해 다중 디바이스에 동시에 작업을 제출한다. 데이터 전송 비용을 최소화하기 위해 입력 행렬과 벡터는 초기 한 번만 GPU 메모리로 복사하고, 이후 반복 단계에서는 필요한 부분만 호스트와 디바이스 간에 교환한다. 다중 GPU 환경에서는 각 디바이스가 독립적인 서브 행렬을 담당하도록 파티셔닝되며, Gaspard2가 생성한 스케줄러가 작업 간 의존성을 분석해 동기화 포인트를 자동 삽입한다.
실험에서는 2.26 GHz Intel Core 2 Duo와 NVIDIA Tesla T10 4개 GPU가 장착된 S1070을 사용하였다. 기준선은 Matlab의 pcg 함수(단일 CPU)이며, 자동 생성된 OpenCL 구현은 1, 2, 4 GPU 각각에 대해 0.659 s, 0.461 s, 0.380 s의 실행 시간을 기록했다. 이는 순차 구현 대비 각각 4.81배, 6.87배, 8.34배의 GFLOPS 향상을 의미한다. 다중 GPU 확장은 선형적 가속을 기대하기 어려운 점(데이터 전송 및 동기화 오버헤드)에도 불구하고, 4 GPU 사용 시 2.5배 정도의 실질적인 속도 향상을 달성했다.
이 접근법의 장점은 (1) 비전문가도 UML‑MARTE 모델만으로 병렬 코드를 생성할 수 있어 개발 기간을 크게 단축한다, (2) 모델 재사용성을 통해 새로운 알고리즘이나 하드웨어 아키텍처에 대한 포팅이 용이하다, (3) 자동화된 작업 분할과 스케줄링이 다중 GPU 자원을 효율적으로 활용한다는 점이다. 한편 한계점으로는 자동 생성된 커널이 손수 최적화된 코드에 비해 미세한 성능 차이가 존재하고, 복잡한 데이터 의존성을 가진 알고리즘에서는 모델링 단계에서 추가적인 제약 정의가 필요할 수 있다. 향후 연구에서는 하이퍼그래프 기반 파티셔닝 기법을 통합하거나, OpenCL 외에 SYCL·Kokkos와 같은 최신 이식성 프레임워크와의 연계도 검토할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기