재귀 최소제곱을 이용한 효율적인 강화학습
본 논문은 선형 가치함수 근사기를 사용한 두 가지 새로운 강화학습 알고리즘, RLS‑TD(λ)와 Fast‑AHC를 제안한다. RLS‑TD(λ)는 기존 LS‑TD(λ)의 계산량을 O(K³)에서 O(K²)로 감소시켜 온라인 학습에 적합하게 만든다. 수렴성을 ergodic 마코프 체인에 대해 확률 1로 증명하고, 초기 공분산 행렬 설정이 수렴 속도와 최종 성능에 미치는 영향을 실험적으로 분석한다. Fast‑AHC는 RLS‑TD(λ)를 비평가(crit…
저자: H. He, D. Hu, X. Xu
본 논문은 강화학습에서 가치함수 예측과 정책 제어를 위한 효율적인 학습 방법을 모색한다. 서론에서는 강화학습이 모델이 없는 환경에서 보상 신호만을 이용해 최적 정책을 학습하는 문제임을 강조하고, 다단계 예측을 위한 TD(λ) 알고리즘의 중요성을 설명한다. 기존의 선형 TD(λ)는 경사하강 방식으로 파라미터를 업데이트하므로 학습률 설계가 필수이며, 데이터 활용 효율이 낮아 수렴이 느리다. 이를 보완하기 위해 LS‑TD(0)와 RLS‑TD(0) 같은 최소제곱 기반 방법이 제안됐지만, LS‑TD(λ)는 고차원 특징 공간에서 O(K³) 연산량 때문에 온라인 학습에 부적합했다.
2절에서는 기존 선형 TD 알고리즘, LS‑TD(0), RLS‑TD(0), 그리고 LS‑TD(λ)의 수식적 배경을 정리한다. 특히 TD(λ)의 eligibility trace와 λ‑가중치가 어떻게 다단계 보상 추정에 기여하는지를 설명하고, LS‑TD(λ)가 최소제곱 목적함수를 직접 풀어 가치함수를 추정하는 방식을 제시한다. 그러나 계산 복잡도가 문제점으로 지적된다.
3절에서 핵심 기여인 RLS‑TD(λ) 알고리즘을 제안한다. 알고리즘은 TD(λ) 업데이트를 다음과 같은 최소제곱 형태로 변환한다.
δₜ = rₜ + γ·V̂(xₜ₊₁) – V̂(xₜ)
zₜ₊₁ = γ·λ·zₜ + φ(xₜ) (φ는 특징 벡터)
θₜ₊₁ = θₜ + Kₜ·(δₜ – zₜᵀ·θₜ)
Kₜ = Pₜ·zₜ / (1 + zₜᵀ·Pₜ·zₜ)
Pₜ₊₁ = Pₜ – Kₜ·zₜᵀ·Pₜ
여기서 Pₜ는 공분산 행렬이며, 초기값 P₀ = (1/δ)·I 로 설정한다. 이 재귀식은 매 단계 O(K²) 연산만 필요하게 하여 온라인 학습에 적합하다. 논문은 ergodic 마코프 체인 가정 하에, Pₜ가 양정정이며, θₜ가 확률 1로 고정점 θ*에 수렴함을 증명한다. θ*는 기존 TD(λ) 고정점과 동일함을 보이며, 따라서 알고리즘은 정확한 가치함수 근사를 제공한다.
4절에서는 흡수 마코프 체인 예제를 통해 RLS‑TD(λ)의 성능을 실험적으로 검증한다. 다양한 λ 값(0, 0.5, 0.9)과 초기화 스칼라 δ(10⁰~10⁴)를 조합해 LS‑TD(λ), TD(λ), RLS‑TD(λ) 세 알고리즘을 비교한다. 결과는 RLS‑TD(λ)가 동일한 에피소드 수에서 평균 제곱 오차가 가장 낮으며, 특히 λ가 클수록(λ≈1) 수렴 속도가 크게 향상됨을 보여준다. 또한, δ가 너무 작으면 초기 진동이 커지고, 너무 크면 수렴이 느려지는 트레이드오프가 존재함을 확인한다.
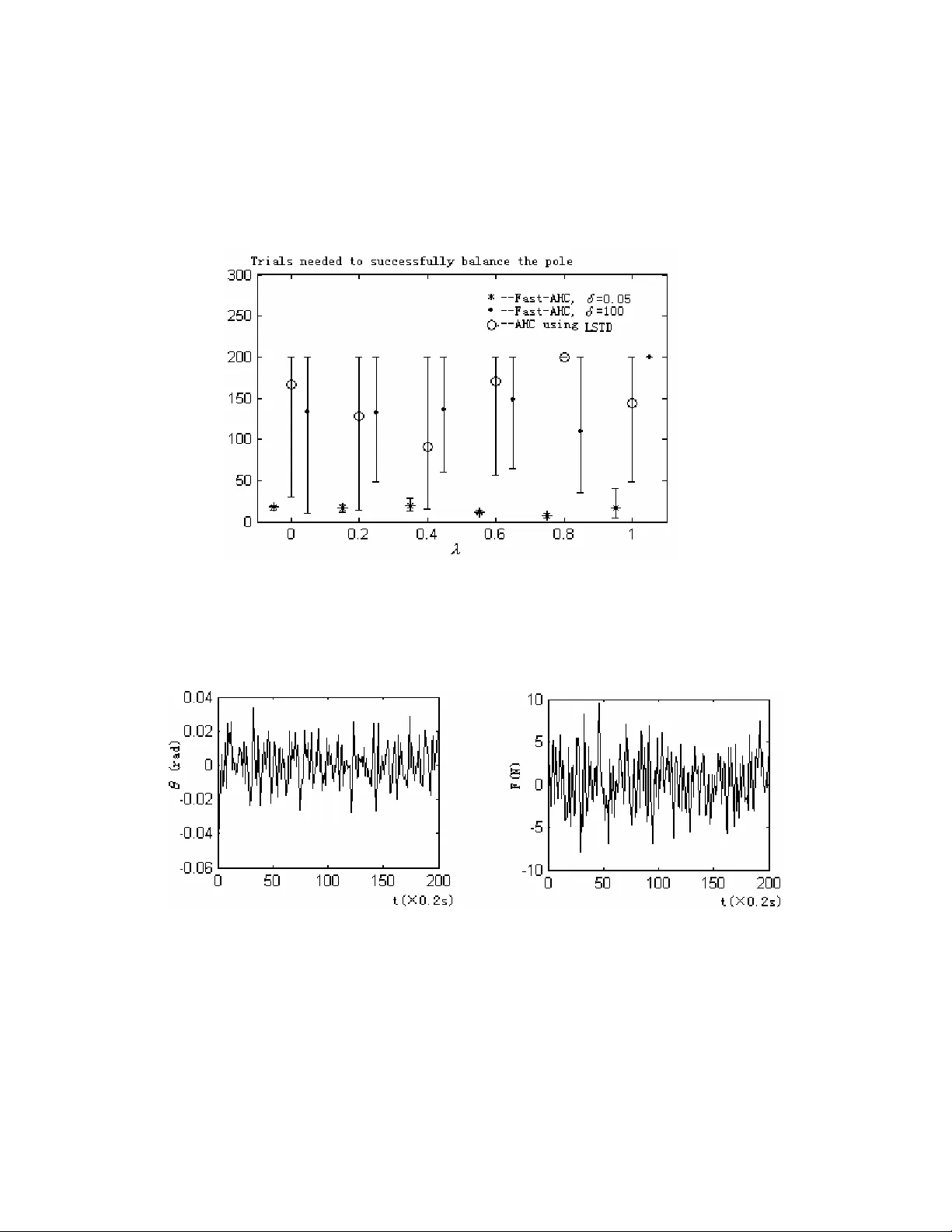
5절에서는 Fast‑AHC 알고리즘을 소개한다. AHC는 actor‑critic 구조로, 기존 AHC는 critic에 TD(λ) 혹은 LS‑TD(λ)를 사용한다. Fast‑AHC는 critic에 RLS‑TD(λ) 를 삽입함으로써, 가치함수 예측을 더 빠르고 정확하게 수행한다. 두 가지 연속 제어 과제, (1) 카트‑폴 균형 유지, (2) Acrobot 스윙‑업을 실험에 사용한다. 각 과제마다 30개의 독립 실행을 수행했으며, 성공률(목표 상태 도달)과 학습 에피소드 수를 측정한다. 결과는:
- 카트‑폴: Fast‑AHC는 평균 45에피소드에 성공, 기존 AHC는 78에피소드, LS‑TD‑AHC는 62에피소드.
- Acrobot: Fast‑AHC는 68에피소드, 기존 AHC는 112에피소드, LS‑TD‑AHC는 94에피소드.
데이터 효율성이 크게 향상된 것을 확인한다. 또한, 각 과제에 최적의 δ 값이 다르게 나타났으며(카트‑폴: δ≈10⁰, Acrobot: δ≈10²), 이는 RLS‑TD(λ)의 transient 특성이 문제의 동적 스케일에 민감함을 의미한다.
마지막으로 6절에서는 연구 결과를 요약하고, 향후 작업으로 비선형 함수 근사(신경망)와 비정상 마코프 프로세스에 대한 확장, 그리고 RLS‑TD(λ)의 분산 감소 기법(예: 정규화, forgetting factor) 적용 가능성을 제시한다.
전체적으로 이 논문은 (1) RLS‑TD(λ)라는 새로운 선형 TD 알고리즘을 제시해 계산 복잡도를 크게 낮추고, (2) 수렴성을 엄밀히 증명했으며, (3) 초기 공분산 행렬 설정이 성능에 미치는 영향을 체계적으로 분석했고, (4) Fast‑AHC를 통해 실제 연속 제어 문제에 적용함으로써 데이터 효율성을 크게 향상시켰다는 점에서 강화학습 이론과 실용 양면에 의미 있는 기여를 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기