다중작업 PU 학습 기반 질병 유전자 우선순위 지정 ProDiGe
ProDiGe는 알려진 질병 유전자와 후보 유전자 사이의 유사성을 PU(Positive‑Unlabeled) 학습으로 모델링하고, 다중작업 학습을 통해 질병 간 정보를 공유한다. 다양한 유전자 특성(시퀀스, 발현, PPI 등)을 커널 통합으로 결합해 전 유전체 수준에서 후보 유전자를 순위화한다. 실험 결과, 기존 방법인 Endeavour와 PRINCE보다 높은 재현율을 보이며 특히 알려진 유전자가 없는 희귀 질환에서도 좋은 성능을 나타낸다.
저자: Fantine Mordelet (CBIO, CREST), Jean-Philippe Vert (CBIO)
본 논문은 인간 질병 유전자를 효율적으로 우선순위 지정하기 위한 새로운 알고리즘인 ProDiGe를 제안한다. 전통적인 연결 분석이나 최신 고처리량 기술은 수십에서 수백 개에 이르는 후보 유전자를 도출하지만, 실제 원인 유전자를 찾는 과정은 비용과 시간이 많이 든다. 따라서 풍부한 생물학적 데이터베이스를 활용해 후보 유전자를 자동으로 순위화하는 컴퓨팅 방법이 필요하다.
ProDiGe는 세 가지 주요 혁신을 갖는다. 첫째, 양성‑미라벨(Positive‑Unlabeled, PU) 학습 프레임워크를 도입한다. 기존의 1‑클래스 SVM이나 라벨 전파 방식은 양성(이미 알려진 질병 유전자)만을 이용하거나 전체 네트워크 구조에 의존한다. PU‑SVM은 양성 샘플과 라벨이 없는 전체 유전자 집합을 동시에 고려해, 양성에 가까운 미라벨을 높은 점수로 매긴다. 이는 특히 양성 샘플이 극히 적은 상황에서도 강인한 순위 매김을 가능하게 한다.
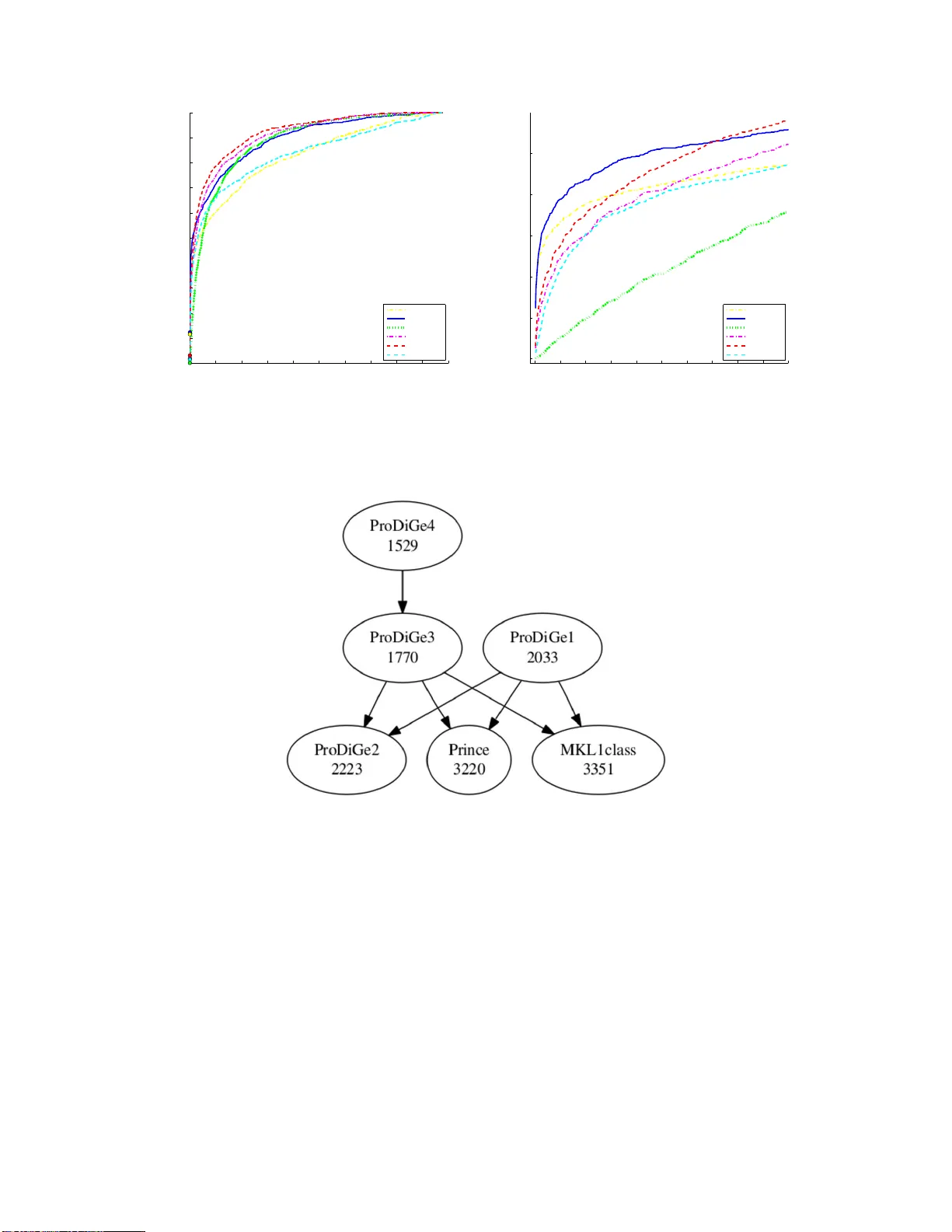
둘째, 다중작업 학습(Multi‑Task Learning)을 통해 질병 간 정보를 공유한다. ProDiGe2는 모든 질병에 대해 동일한 작업 관계를 가정하고, ProDiGe3은 질병 페노타입 유사도 행렬을 커널에 삽입해 작업 간 가중치를 조정한다. ProDiGe4는 여기서 디렉 커널을 추가해 페노타입이 거의 동일한 질병들 사이의 과도한 공유를 억제한다. 이러한 설계는 ‘orphan disease’라 불리는, 알려진 유전자가 전혀 없는 질환에서도 관련 유전자를 추정할 수 있게 한다.
셋째, 이질적인 유전자 특성을 커널 방법으로 통합한다. 저자는 9개의 데이터 소스(발현 프로파일, 기능 주석, 단백질‑단백질 상호작용, 전사인자 결합 모티프, 도메인, 문헌 등)를 각각 커널 함수로 변환하고, 두 가지 통합 전략(단순 평균 커널, 다중 커널 학습(MKL))을 비교했다. 실험 결과 평균 커널이 계산 효율이 높고 성능 차이가 미미해 최종 실험에 채택되었다.
성능 평가는 OMIM 데이터베이스에서 추출한 2,544개의 질병‑유전자 연관성을 대상으로 LOOCV(Leave‑One‑Out Cross‑Validation)를 수행했다. 각 질병에 대해 하나의 알려진 유전자를 제외하고 모델을 학습한 뒤, 전체 19,540개의 유전자에 대해 순위를 매겼다. ProDiGe1(평균 커널)과 ProDiGe1‑MKL는 기존 MKL1Class(양성‑전용 1‑클래스 SVM)보다 유의하게 높은 재현율을 보였으며, 상위 20개 후보(전체의 0.1%) 안에 약 30%의 정답을 포함했다.
다중작업 변형인 ProDiGe3·4는 정보 공유를 허용했을 때 평균 순위가 크게 개선되어, ProDiGe4가 가장 낮은 평균 순위(≈1,682)를 기록했다. 이는 페노타입 유사도를 활용한 작업 가중치가 질병 간 지식 전이에 큰 효과를 주는 것을 의미한다.
또한, 동일한 PPI 커널만을 사용한 ProDiGe‑PPI와 PRINCE를 비교했을 때, 두 방법의 전반적인 성능은 비슷했지만, 낮은 순위 구간(상위 5~10%)에서는 PU‑SVM 기반인 ProDiGe‑PPI가 PRINCE보다 현저히 우수했다. 이는 PU 학습이 라벨 전파 방식보다 희소 양성 샘플을 활용하는 데 더 강력함을 시사한다.
결론적으로 ProDiGe는 (1) PU 학습을 통한 효율적인 양성‑미라벨 모델링, (2) 다중작업 커널을 이용한 질병 간 지식 전이, (3) 커널 기반 이질 데이터 통합이라는 세 축을 결합해 기존 방법 대비 실질적인 성능 향상을 달성하였다. 향후 연구에서는 더 정교한 페노타입 매트릭스와 추가적인 오믹스 데이터(예: 메타볼로믹스, 에피제네틱스)를 포함시켜 모델을 확장할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기