페이스북 크롤링으로 보는 대규모 소셜 네트워크 분석
초록
본 논문은 프라이버시를 준수하면서 자체 개발한 크롤러를 이용해 페이스북의 친구 관계를 무방향 그래프로 수집·분석한다. BFS와 Uniform 샘플링 두 가지 방법을 비교하고, 샘플링 편향, 데이터 정제, 그래프 특성(차수 분포, 중심성, 스케일링 법칙 등)을 평가한다.
상세 분석
이 연구는 온라인 소셜 네트워크(OSN) 데이터를 대규모로 확보하기 위한 두 가지 샘플링 전략을 실험적으로 검증한다. 첫 번째는 전통적인 너비 우선 탐색(BFS) 방식으로, seed 노드에서 시작해 친구‑친구‑친구까지 3단계 깊이까지 확장한다. BFS는 고차원 노드(고차수 사용자)를 과대평가하는 편향을 내포한다는 기존 연구(Kurant 등)의 지적을 반영해, 240시간 제한과 3단계 깊이 제한을 두어 실용적인 수집량을 확보한다. 두 번째는 Uniform 샘플링으로, 페이스북이 32비트 사용자 ID 체계를 사용한다는 점을 활용해 무작위 ID를 생성하고 존재 여부를 확인한다. 이 방식은 사용자 ID와 친구 관계 분포가 독립적이라는 가정 하에 편향이 최소화된다고 주장한다. 실제 구현에서는 2³² 범위에서 2¹⁶ × 65.5 K개의 ID를 무작위 추출해 8개의 에이전트가 10일간 병렬 크롤링을 수행했으며, 평균 8번 시도당 1개의 유효 사용자 프로필을 확보했다.
데이터 수집 파이프라인은 (1) 크롤러 초기화, (2) 인증 쿠키 확보, (3) 친구 리스트 페이지 요청, (4) 정규표현식 기반 파싱, (5) 중복 제거·그래프ML 포맷 변환 순으로 설계되었다. 프라이버시 정책을 고려해 공개된 친구 리스트만을 대상으로 하였으며, 페이스북이 한 번에 반환하는 친구 수를 400명으로 제한하는 서버‑사이드 제약을 우회하기 위해 페이지네이션을 반복적으로 호출한다.
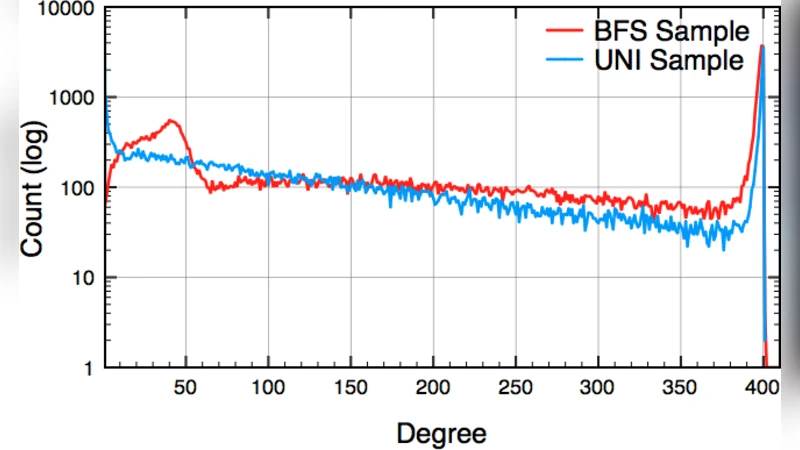
수집된 두 샘플은 각각 약 63.4 K(DFS)와 2¹⁶ × 65.5 K(Uniform)개의 고유 사용자를 포함한다. 이후 저자들은 SNA 도구를 활용해 차수 분포가 파워‑법칙을 따르는지, 클러스터링 계수와 평균 경로 길이가 실제 페이스북 통계와 일치하는지 검증한다. 특히, BFS 샘플은 고차수 노드 비중이 과대평가되는 반면, Uniform 샘플은 전체 네트워크의 스케일링 특성을 보다 정확히 재현한다는 결론을 도출한다. 또한, 데이터 정제 과정에서 비공개 프로필이나 친구 리스트가 제한된 경우를 식별하고, 이러한 결측치를 그래프 구조 분석에 미치는 영향을 최소화하기 위한 보정 방법을 제시한다.
연구는 대규모 OSN 데이터를 수집할 때 기술적·법적 제약을 어떻게 관리할 수 있는지, 그리고 샘플링 방법 선택이 분석 결과에 미치는 영향을 실증적으로 보여준다. 특히, 무작위 ID 기반 Uniform 샘플링이 대규모 그래프의 전반적 특성을 파악하는 데 효과적이며, BFS는 특정 지역(예: 커뮤니티 내부) 분석에 유리하다는 실용적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기