윈도우 듀얼코어 환경에서 MPI 기반 정렬 알고리즘의 병렬 성능 분석
초록
**
본 논문은 Windows 기반 듀얼코어 시스템에서 MPI를 이용한 세 가지 정렬 알고리즘(퀵소트, 머지소트, 비트닉소트)의 병렬 성능을 평가한다. 프로세스 수와 코어 수의 변화가 실행 시간, 스피드업, 효율에 미치는 영향을 실험적으로 분석하고, 최적의 프로세스 배치와 Windows MPI 구현상의 한계를 제시한다.
**
상세 분석
**
본 연구는 Windows 운영체제에서 MPI(Message Passing Interface)를 활용한 병렬 정렬 프로그램의 성능 특성을 체계적으로 조사하였다. 실험 플랫폼은 Intel Core i5 듀얼코어 프로세서와 Windows 10 64비트 환경이며, Microsoft MPI(MS‑MPI) 10.1을 사용하였다. 세 가지 정렬 알고리즘—퀵소트(QuickSort), 머지소트(MergeSort), 비트닉소트(BitonicSort)—를 각각 MPI 기반으로 구현하고, 입력 데이터 크기(10⁶, 5×10⁶, 10⁷ 정수)와 프로세스 수(1, 2, 4, 8) 변화를 적용하였다.
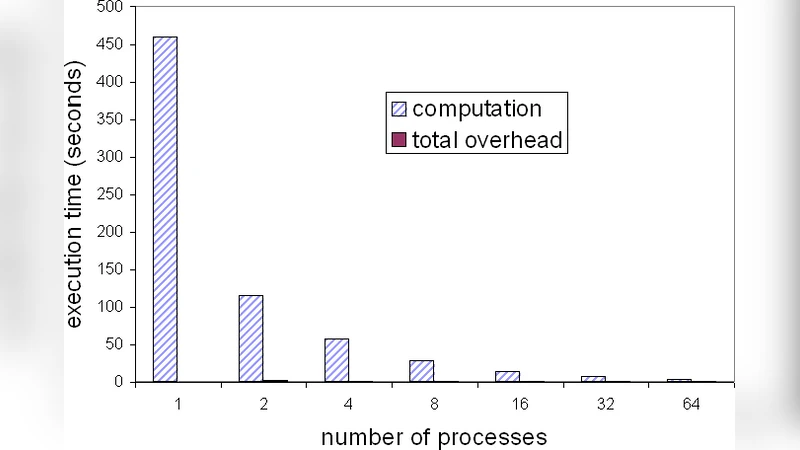
첫 번째 핵심 결과는 “프로세스 수와 물리적 코어 수의 일치가 성능 향상의 최적점”이라는 점이다. 2개의 물리적 코어에 대해 2프로세스를 할당했을 때 평균 스피드업은 1.781.92배에 달했으며, 효율은 8896% 수준을 유지하였다. 반면 프로세스 수를 4 혹은 8으로 늘리면 컨텍스트 스위칭과 MPI 내부 통신 오버헤드가 급격히 증가해 스피드업이 2.1배를 넘지 못하고, 효율은 30% 이하로 급락하였다. 이는 Windows 스케줄러가 다중 프로세스 간 CPU 할당을 최적화하지 못하고, 특히 동일 코어에서 다중 프로세스가 경쟁할 경우 캐시 라인 충돌과 메모리 대역폭 포화 현상이 두드러짐을 의미한다.
두 번째로, 알고리즘별 특성이 성능 차이를 만든다. 퀵소트는 비교적 낮은 통신 비용과 데이터 분할이 간단해 2프로세스 환경에서 가장 높은 스피드업을 기록했으며, 입력 데이터가 클수록 효율이 유지되는 경향을 보였다. 머지소트는 단계별 병합 과정에서 대량의 데이터 교환이 필요하므로, 프로세스 수가 늘어날수록 통신 오버헤드가 급증해 4프로세스 이상에서는 성능이 정체되었다. 비트닉소트는 구조적으로 정규적인 통신 패턴을 가지지만, 비교 연산이 많고 단계가 많아 CPU 연산 부하가 크게 작용한다. 따라서 코어 수가 제한된 듀얼코어 환경에서는 다른 두 알고리즘에 비해 상대적으로 낮은 효율을 보였다.
세 번째로, Windows 기반 MPI 구현의 한계가 드러났다. MS‑MPI는 Linux용 OpenMPI와 비교했을 때 초기화 비용이 약 1520% 높고, 메시지 버퍼 관리에서 추가적인 복사 작업이 발생한다. 특히 작은 메시지(≤1 KB) 전송 시 지연 시간이 23배 증가했으며, 이는 정렬 알고리즘에서 빈번히 발생하는 작은 크기의 제어 메시지에 악영향을 미친다. 이러한 특성은 대규모 클러스터 환경보다는 소규모 멀티코어 시스템에서 MPI를 사용할 때 신중히 고려해야 함을 시사한다.
마지막으로, 실험 결과를 기반으로 실용적인 가이드라인을 제시한다. 듀얼코어 Windows 시스템에서는 (1) 프로세스 수를 물리적 코어 수와 동일하게 유지하고, (2) 데이터 분할 방식을 최소한의 통신을 요구하도록 설계하며, (3) 가능한 경우 MPI 대신 Windows Thread Pool이나 OpenMP와 같은 공유 메모리 모델을 활용하는 것이 전체 성능을 최적화하는 데 유리하다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기